Valhalla's Things: Blog updates
Tags: madeof:bits, meta
src for images got deleted instead of properly converted.
src for images got deleted instead of properly converted.
| Publisher: | Dutton Books |
| Copyright: | February 2019 |
| Printing: | 2020 |
| ISBN: | 0-7352-3190-7 |
| Format: | Kindle |
| Pages: | 339 |
| Publisher: | Fairwood Press |
| Copyright: | November 2023 |
| ISBN: | 1-958880-16-7 |
| Format: | Kindle |
| Pages: | 257 |

 Over roughly the last year and a half I have been participating as a reviewer in
ACM s Computing Reviews, and have even
been honored as a Featured
Reviewer.
Given I have long enjoyed reading friends reviews of their reading material
(particularly, hats off to the very active Russ
Allbery, who both beats all of my
frequency expectations (I could never sustain the rythm he reads to!) and holds
documented records for his >20 years as a book reader, with far more clarity and
readability than I can aim for!), I decided to explicitly share my reviews via
this blog, as the audience is somewhat congruent; I will also link here some
reviews that were not approved for publication, clearly marking them so.
I will probably work on wrangling my Jekyll site
to display an (auto-)updated page and RSS feed for the reviews. In the meantime,
the reviews I have published are:
Over roughly the last year and a half I have been participating as a reviewer in
ACM s Computing Reviews, and have even
been honored as a Featured
Reviewer.
Given I have long enjoyed reading friends reviews of their reading material
(particularly, hats off to the very active Russ
Allbery, who both beats all of my
frequency expectations (I could never sustain the rythm he reads to!) and holds
documented records for his >20 years as a book reader, with far more clarity and
readability than I can aim for!), I decided to explicitly share my reviews via
this blog, as the audience is somewhat congruent; I will also link here some
reviews that were not approved for publication, clearly marking them so.
I will probably work on wrangling my Jekyll site
to display an (auto-)updated page and RSS feed for the reviews. In the meantime,
the reviews I have published are:
 This is a post I wrote in June 2022, but did not publish back then.
After first publishing it in December 2023, a perfectionist insecure
part of me unpublished it again. After receiving positive feedback, i
slightly amended and republish it now.
In this post, I talk about unpaid work in F/LOSS, taking on the example
of hackathons, and why, in my opinion, the expectation of volunteer work
is hurting diversity.
Disclaimer: I don t have all the answers, only some ideas and questions.
This is a post I wrote in June 2022, but did not publish back then.
After first publishing it in December 2023, a perfectionist insecure
part of me unpublished it again. After receiving positive feedback, i
slightly amended and republish it now.
In this post, I talk about unpaid work in F/LOSS, taking on the example
of hackathons, and why, in my opinion, the expectation of volunteer work
is hurting diversity.
Disclaimer: I don t have all the answers, only some ideas and questions.
Indeed, while we have proven that there is a strong and significative correlation between the income and the participation in a free/libre software project, it is not possible for us to pronounce ourselves about the causality of this link.In the French original text:
En effet, si nous avons prouv qu il existe une corr lation forte et significative entre le salaire et la participation un projet libre, il ne nous est pas possible de nous prononcer sur la causalit de ce lien.Said differently, it is certain that there is a relationship between income and F/LOSS contribution, but it s unclear whether working on free/libre software ultimately helps finding a well paid job, or if having a well paid job is the cause enabling work on free/libre software. I would like to scratch this question a bit further, mostly relying on my own observations, experiences, and discussions with F/LOSS contributors.
It is unclear whether working on free/libre software ultimately helps finding a well paid job, or if having a well paid job is the cause enabling work on free/libre software.Maybe we need to imagine this cause-effect relationship over time: as a student, without children and lots of free time, hopefully some money from the state or the family, people can spend time on F/LOSS, collect experience, earn recognition - and later find a well-paid job and make unpaid F/LOSS contributions into a hobby, cementing their status in the community, while at the same time generating a sense of well-being from working on the common good. This is a quite common scenario. As the Flosspols study revealed however, boys often get their own computer at the age of 14, while girls get one only at the age of 20. (These numbers might be slightly different now, and possibly many people don t own an actual laptop or desktop computer anymore, instead they own mobile devices which are not exactly inciting them to look behind the surface, take apart, learn, appropriate technology.) In any case, the above scenario does not allow for people who join F/LOSS later in life, eg. changing careers, to find their place. I believe that F/LOSS projects cannot expect to have more women, people of color, people from working class backgrounds, people from outside of Germany, France, USA, UK, Australia, and Canada on board as long as volunteer work is the status quo and waged labour an earned privilege.
 Intro: Hi, I m Melissa from Igalia and welcome to the Rainbow Treasure Map, a
talk about advanced color management on Linux with AMD/SteamDeck.
Intro: Hi, I m Melissa from Igalia and welcome to the Rainbow Treasure Map, a
talk about advanced color management on Linux with AMD/SteamDeck.
 Useful links: First of all, if you are not used to the topic, you may find
these links useful.
Useful links: First of all, if you are not used to the topic, you may find
these links useful.
 Context: When we talk about colors in the graphics chain, we should keep in
mind that we have a wide variety of source content colorimetry, a variety of
output display devices and also the internal processing. Users expect
consistent color reproduction across all these devices.
The userspace can use GPU-accelerated color management to get it. But this also
requires an interface with display kernel drivers that is currently missing
from the DRM/KMS framework.
Context: When we talk about colors in the graphics chain, we should keep in
mind that we have a wide variety of source content colorimetry, a variety of
output display devices and also the internal processing. Users expect
consistent color reproduction across all these devices.
The userspace can use GPU-accelerated color management to get it. But this also
requires an interface with display kernel drivers that is currently missing
from the DRM/KMS framework.
 Since April, I ve been bothering the DRM community by sending patchsets from
the work of me and Joshua to add driver-specific color properties to the AMD
display driver. In parallel, discussions on defining a generic color management
interface are still ongoing in the community. Moreover, we are still not clear
about the diversity of color capabilities among hardware vendors.
To bridge this gap, we defined a color pipeline for Gamescope that fits the
latest versions of AMD hardware. It delivers advanced color management features
for gamut mapping, HDR rendering, SDR on HDR, and HDR on SDR.
Since April, I ve been bothering the DRM community by sending patchsets from
the work of me and Joshua to add driver-specific color properties to the AMD
display driver. In parallel, discussions on defining a generic color management
interface are still ongoing in the community. Moreover, we are still not clear
about the diversity of color capabilities among hardware vendors.
To bridge this gap, we defined a color pipeline for Gamescope that fits the
latest versions of AMD hardware. It delivers advanced color management features
for gamut mapping, HDR rendering, SDR on HDR, and HDR on SDR.
 AMD/Steam Deck hardware: AMD frequently releases new GPU and APU generations.
Each generation comes with a DCN version with display hardware improvements.
Therefore, keep in mind that this work uses the AMD Steam Deck hardware and its
kernel driver. The Steam Deck is an APU with a DCN3.01 display driver, a DCN3
family.
It s important to have this information since newer AMD DCN drivers inherit
implementations from previous families but aldo each generation of AMD hardware
may introduce new color capabilities. Therefore I recommend you to familiarize
yourself with the hardware you are working on.
AMD/Steam Deck hardware: AMD frequently releases new GPU and APU generations.
Each generation comes with a DCN version with display hardware improvements.
Therefore, keep in mind that this work uses the AMD Steam Deck hardware and its
kernel driver. The Steam Deck is an APU with a DCN3.01 display driver, a DCN3
family.
It s important to have this information since newer AMD DCN drivers inherit
implementations from previous families but aldo each generation of AMD hardware
may introduce new color capabilities. Therefore I recommend you to familiarize
yourself with the hardware you are working on.
 The AMD display driver in the kernel space: It consists of three layers, (1)
the DRM/KMS framework, (2) the AMD Display Manager, and (3) the AMD Display
Core. We extended the color interface exposed to userspace by leveraging
existing DRM resources and connecting them using driver-specific functions for
color property management.
The AMD display driver in the kernel space: It consists of three layers, (1)
the DRM/KMS framework, (2) the AMD Display Manager, and (3) the AMD Display
Core. We extended the color interface exposed to userspace by leveraging
existing DRM resources and connecting them using driver-specific functions for
color property management.
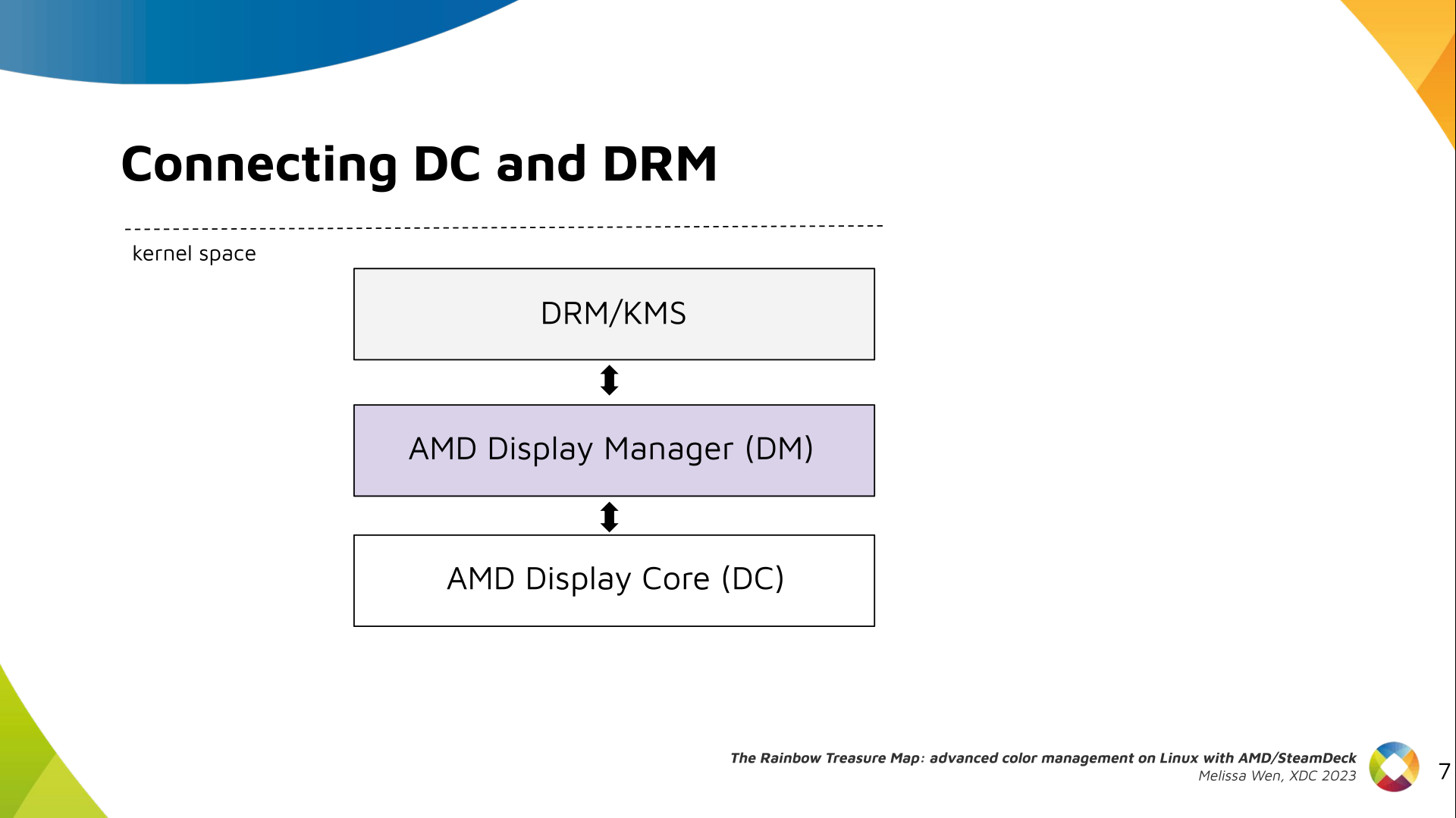 Bridging DC color capabilities and the DRM API required significant changes in
the color management of AMD Display Manager - the Linux-dependent part that
connects the AMD DC interface to the DRM/KMS framework.
Bridging DC color capabilities and the DRM API required significant changes in
the color management of AMD Display Manager - the Linux-dependent part that
connects the AMD DC interface to the DRM/KMS framework.
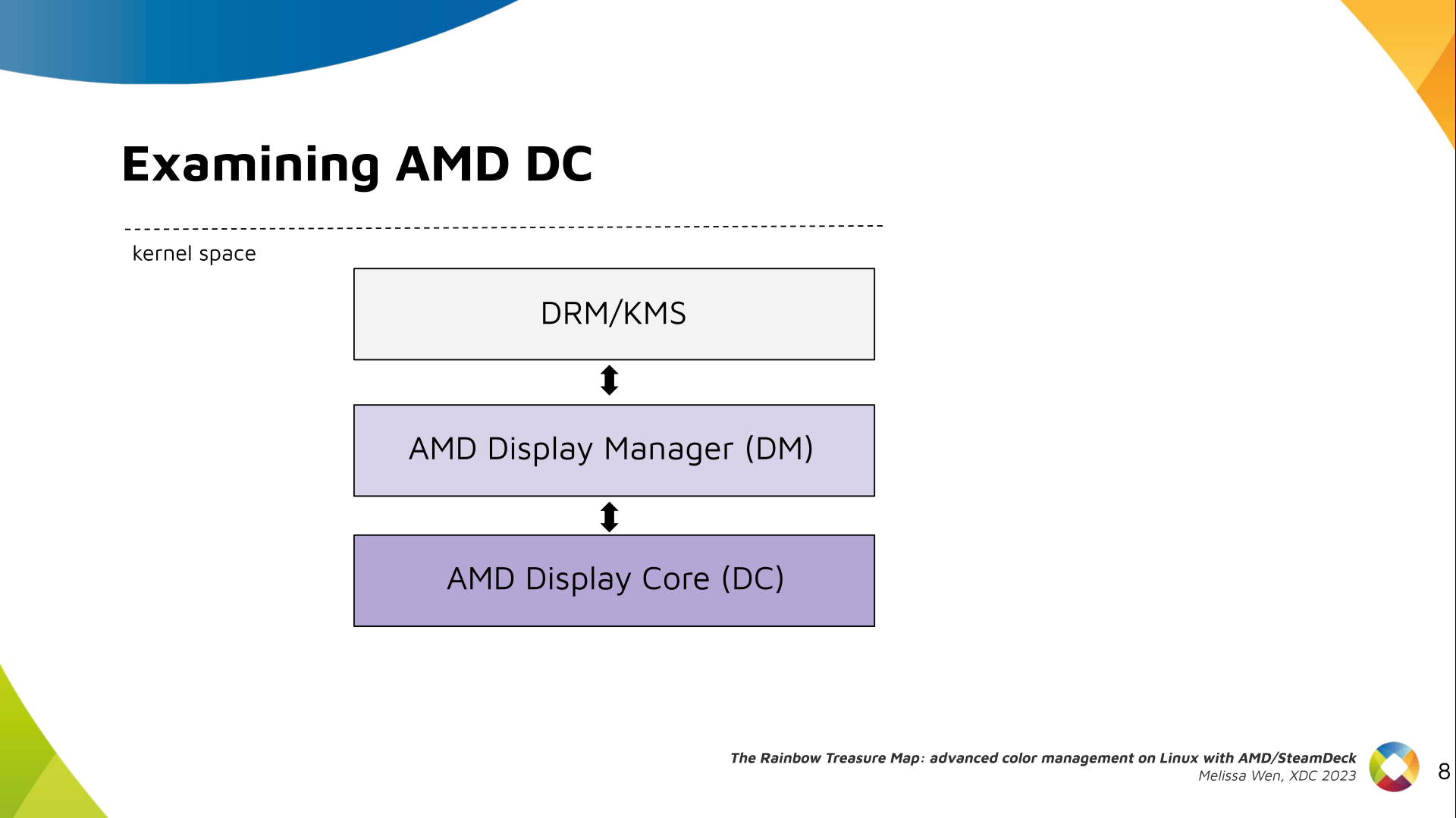 The AMD DC is the OS-agnostic layer. Its code is shared between platforms and
DCN versions. Examining this part helps us understand the AMD color pipeline
and hardware capabilities, since the machinery for hardware settings and
resource management are already there.
The AMD DC is the OS-agnostic layer. Its code is shared between platforms and
DCN versions. Examining this part helps us understand the AMD color pipeline
and hardware capabilities, since the machinery for hardware settings and
resource management are already there.
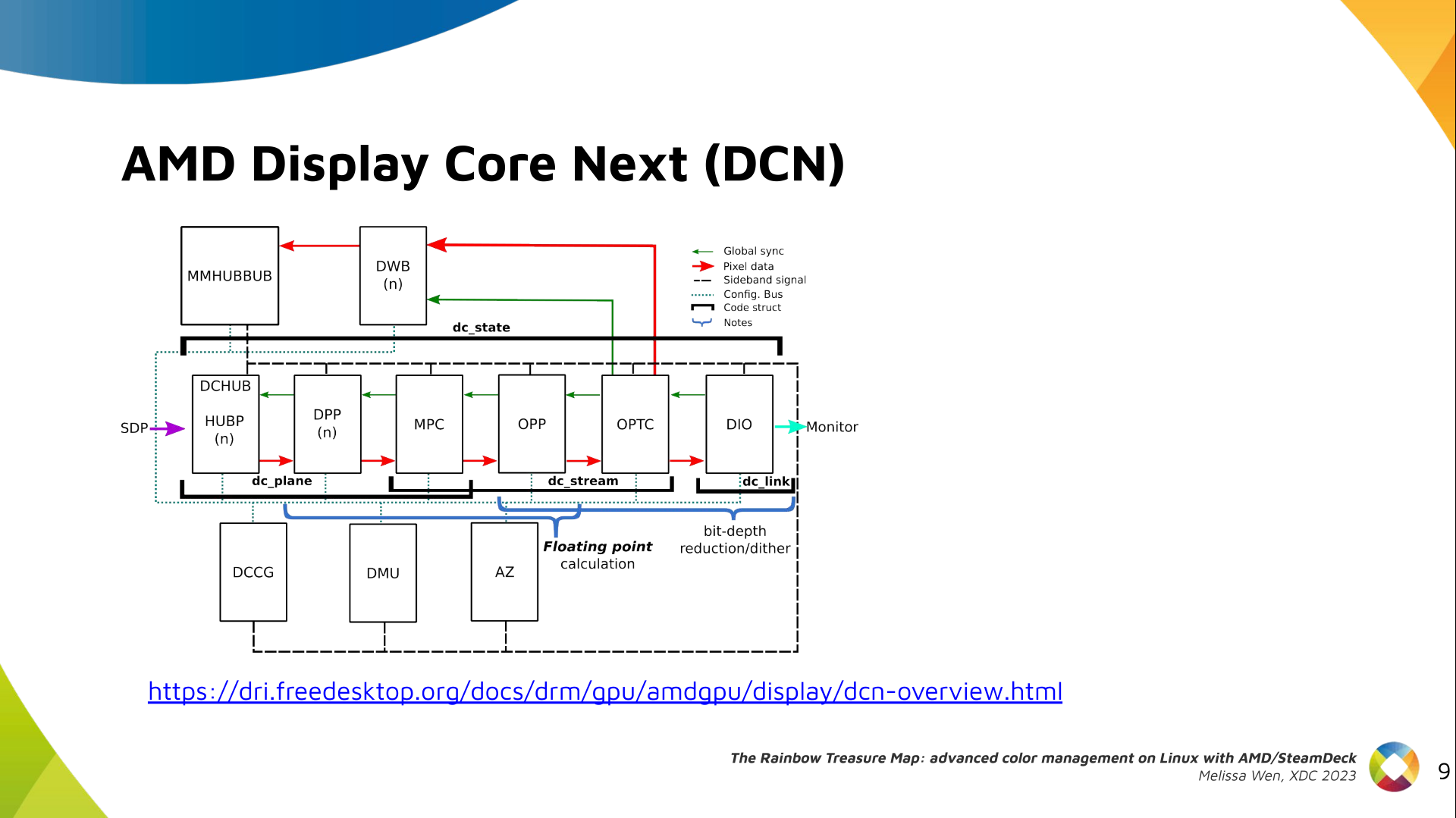 The newest architecture for AMD display hardware is the AMD Display Core Next.
The newest architecture for AMD display hardware is the AMD Display Core Next.
 In this architecture, two blocks have the capability to manage colors:
In this architecture, two blocks have the capability to manage colors:
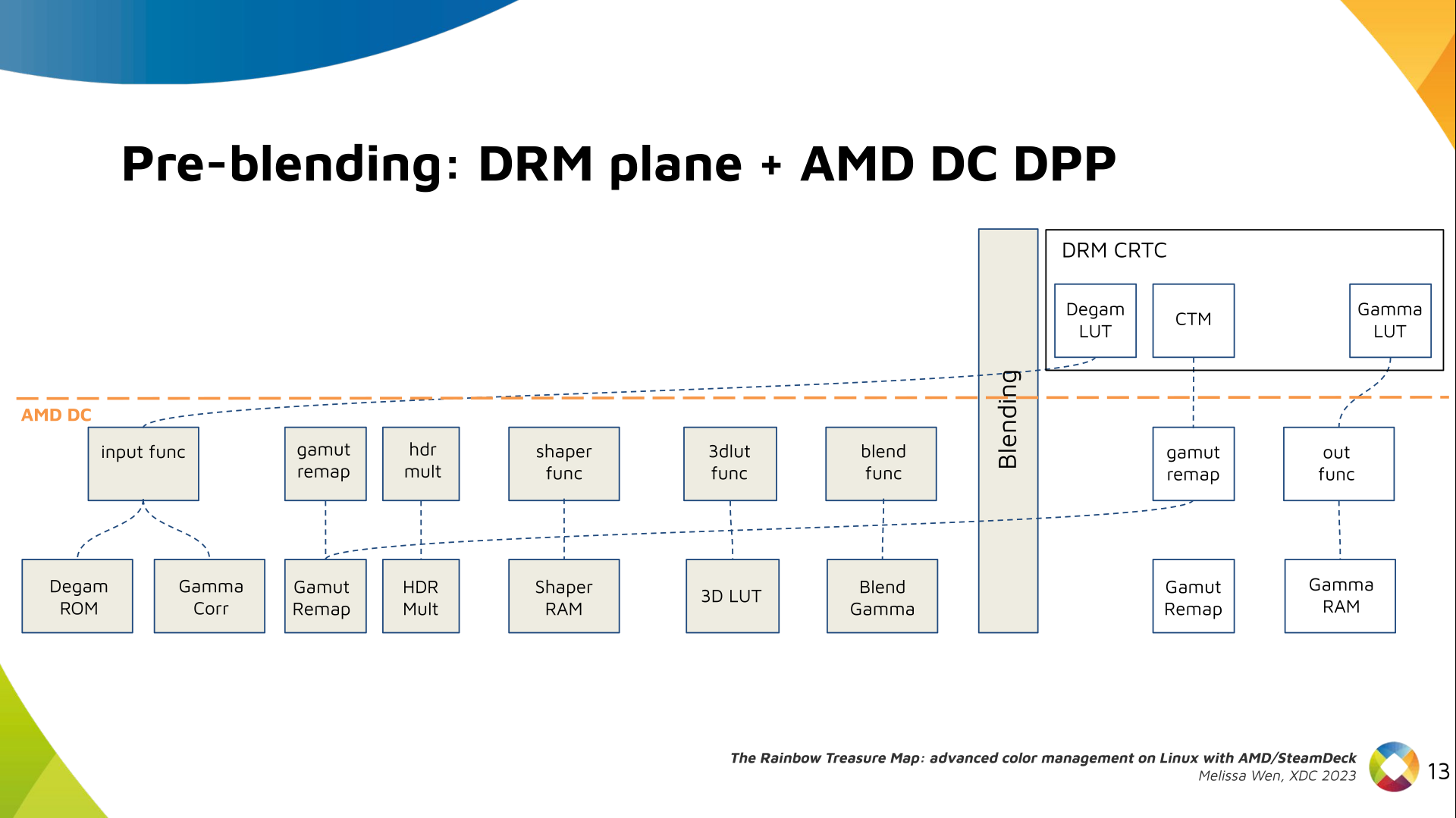
 DRM plane color properties:
This is the DRM color management API before blending.
Nothing!
Except two basic DRM plane properties:
DRM plane color properties:
This is the DRM color management API before blending.
Nothing!
Except two basic DRM plane properties: color_encoding and color_range for
the input colorspace conversion, that is not covered by this work.
 In case you re not familiar with AMD shared code, what we need to do is
basically draw a map and navigate there!
We have some DRM color properties after blending, but nothing before blending
yet. But much of the hardware programming was already implemented in the AMD DC
layer, thanks to the shared code.
In case you re not familiar with AMD shared code, what we need to do is
basically draw a map and navigate there!
We have some DRM color properties after blending, but nothing before blending
yet. But much of the hardware programming was already implemented in the AMD DC
layer, thanks to the shared code.
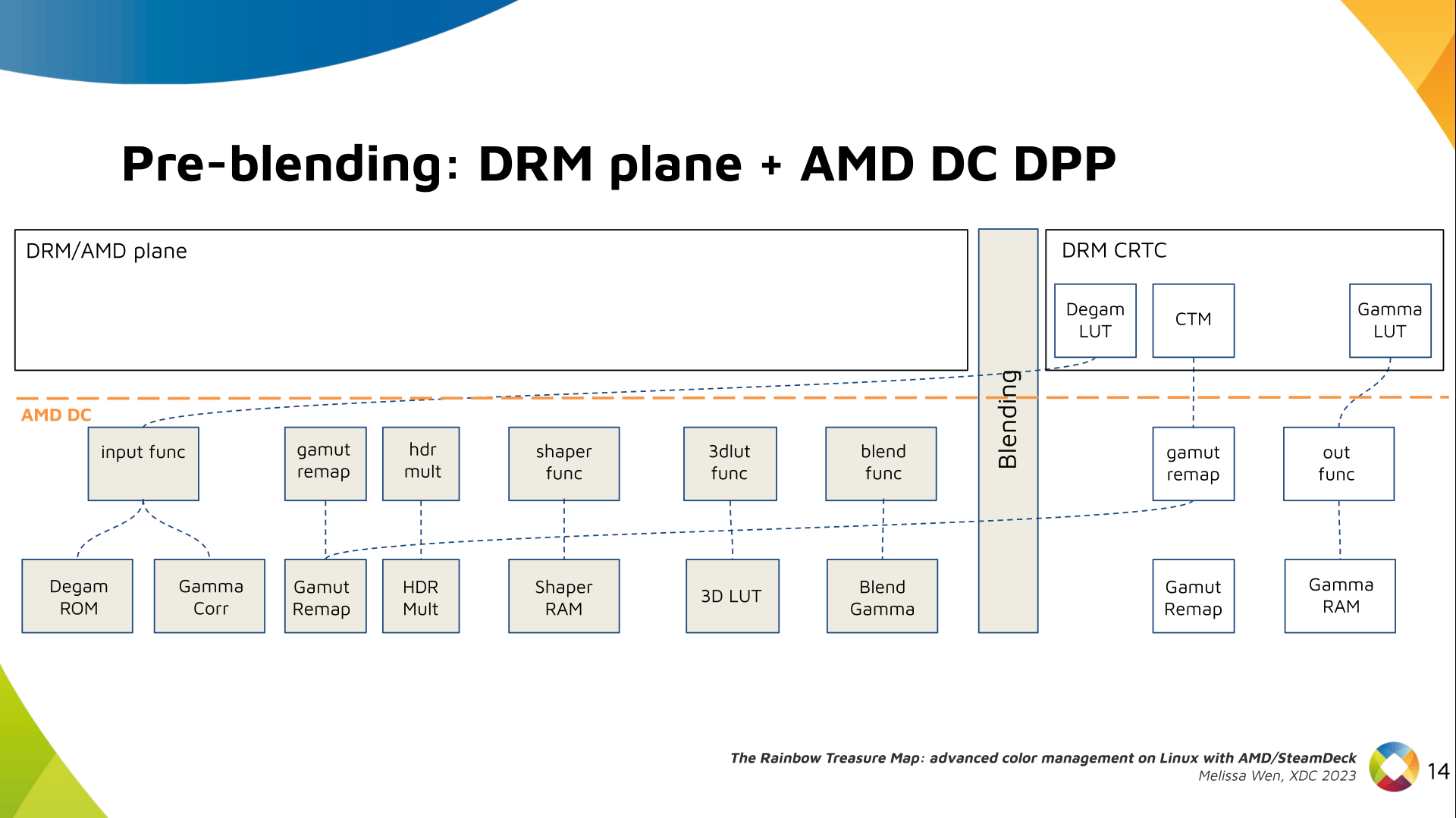 Still both the DRM interface and its connection to the shared code were
missing. That s when the search begins!
Still both the DRM interface and its connection to the shared code were
missing. That s when the search begins!
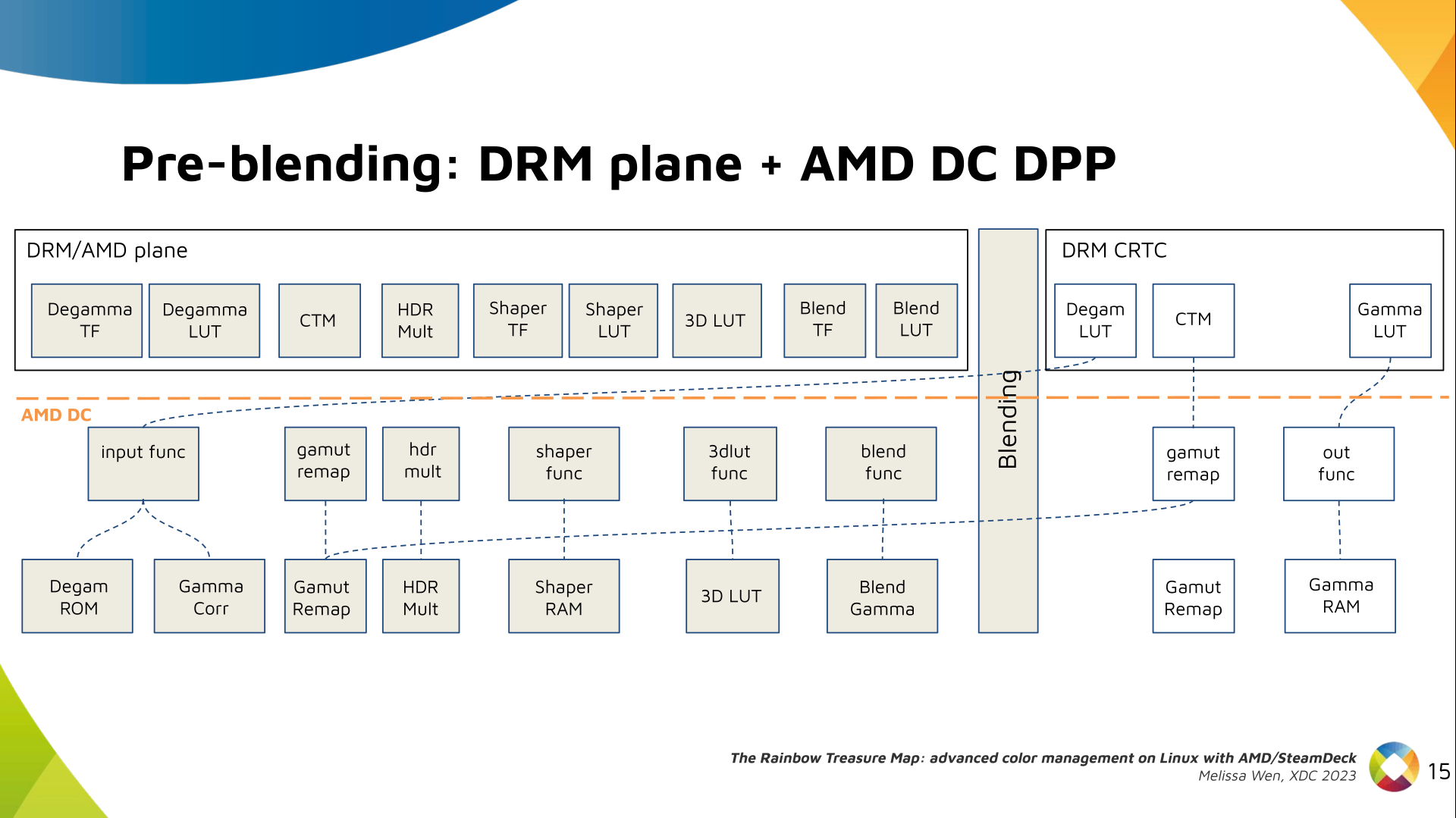 AMD driver-specific color pipeline:
Looking at the color capabilities of the hardware, we arrive at this initial
set of properties. The path wasn t exactly like that. We had many iterations
and discoveries until reached to this pipeline.
AMD driver-specific color pipeline:
Looking at the color capabilities of the hardware, we arrive at this initial
set of properties. The path wasn t exactly like that. We had many iterations
and discoveries until reached to this pipeline.
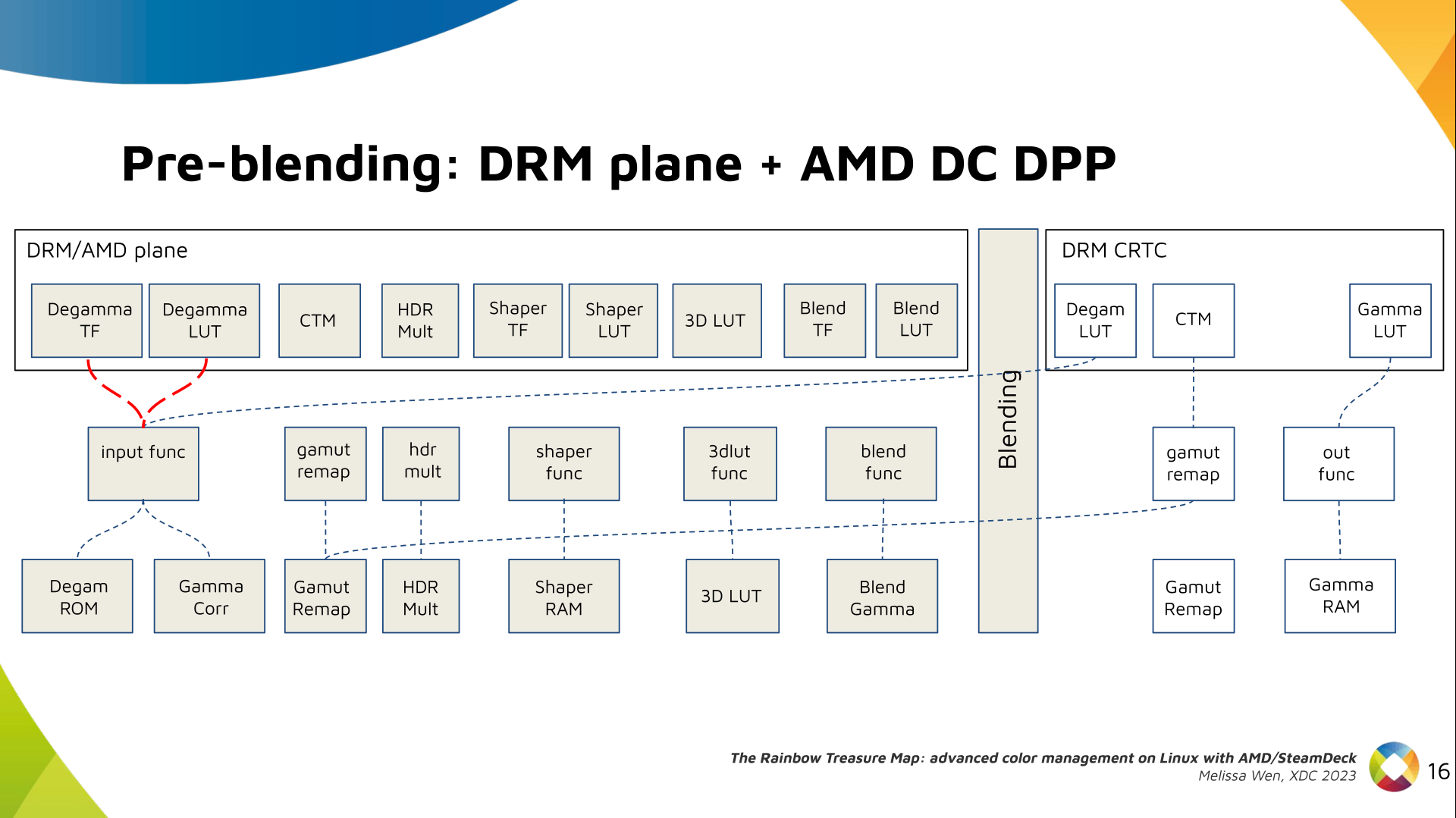 The Plane Degamma is our first driver-specific property before blending. It s
used to linearize the color space from encoded values to light linear values.
The Plane Degamma is our first driver-specific property before blending. It s
used to linearize the color space from encoded values to light linear values.
 We can use a pre-defined transfer function or a user lookup table (in short,
LUT) to linearize the color space.
Pre-defined transfer functions for plane degamma are hardcoded curves that go
to a specific hardware block called DPP Degamma ROM. It supports the following
transfer functions: sRGB EOTF, BT.709 inverse OETF, PQ EOTF, and pure power
curves Gamma 2.2, Gamma 2.4 and Gamma 2.6.
We also have a one-dimensional LUT. This 1D LUT has four thousand ninety six
(4096) entries, the usual 1D LUT size in the DRM/KMS. It s an array of
We can use a pre-defined transfer function or a user lookup table (in short,
LUT) to linearize the color space.
Pre-defined transfer functions for plane degamma are hardcoded curves that go
to a specific hardware block called DPP Degamma ROM. It supports the following
transfer functions: sRGB EOTF, BT.709 inverse OETF, PQ EOTF, and pure power
curves Gamma 2.2, Gamma 2.4 and Gamma 2.6.
We also have a one-dimensional LUT. This 1D LUT has four thousand ninety six
(4096) entries, the usual 1D LUT size in the DRM/KMS. It s an array of
drm_color_lut that goes to the DPP Gamma Correction block.
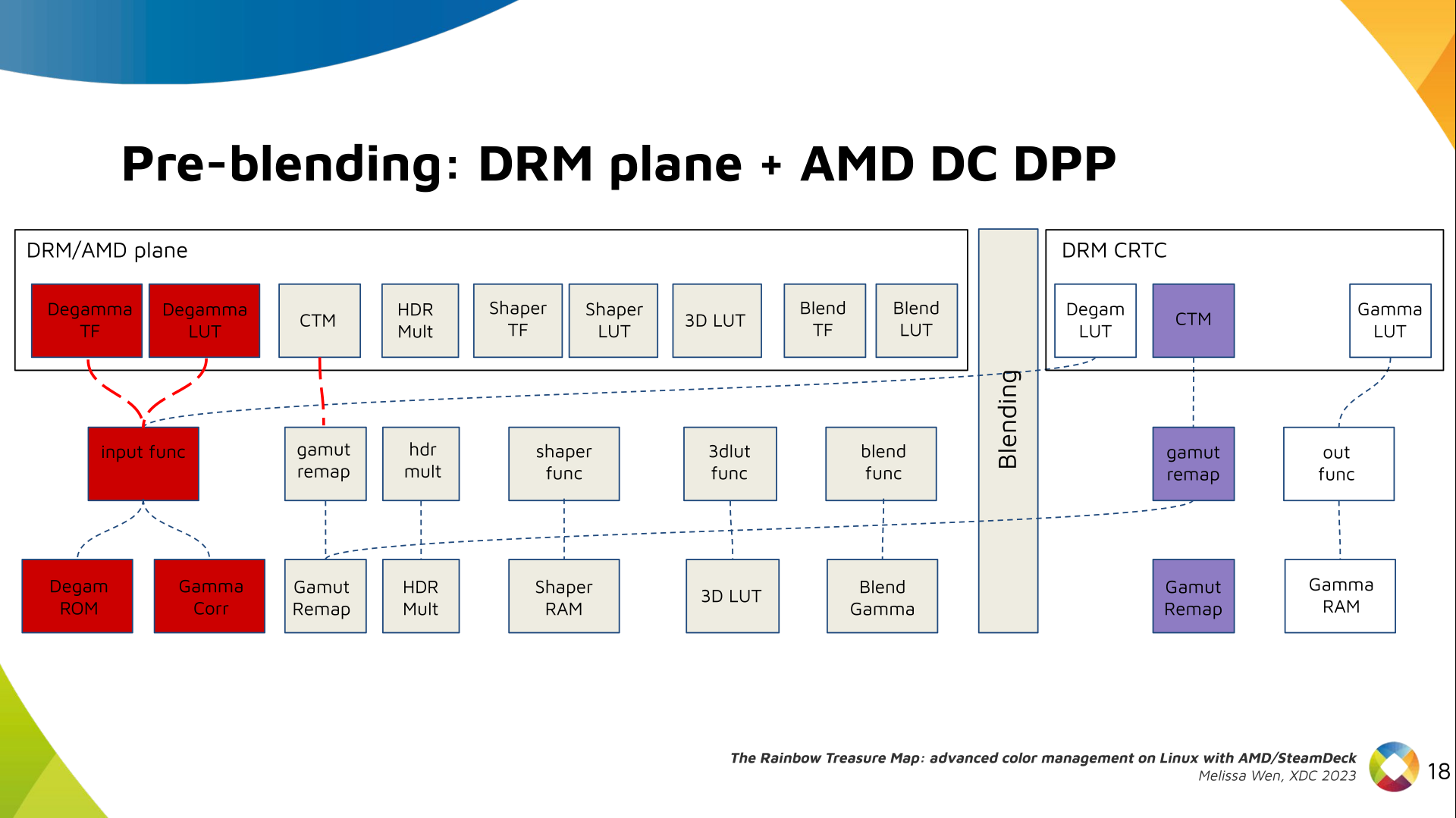 We also have now a color transformation matrix (CTM) for color space
conversion.
We also have now a color transformation matrix (CTM) for color space
conversion.
 It s a 3x4 matrix of fixed points that goes to the DPP Gamut Remap Block.
Both pre- and post-blending matrices were previously gone to the same color
block. We worked on detaching them to clear both paths.
Now each CTM goes on its own way.
It s a 3x4 matrix of fixed points that goes to the DPP Gamut Remap Block.
Both pre- and post-blending matrices were previously gone to the same color
block. We worked on detaching them to clear both paths.
Now each CTM goes on its own way.
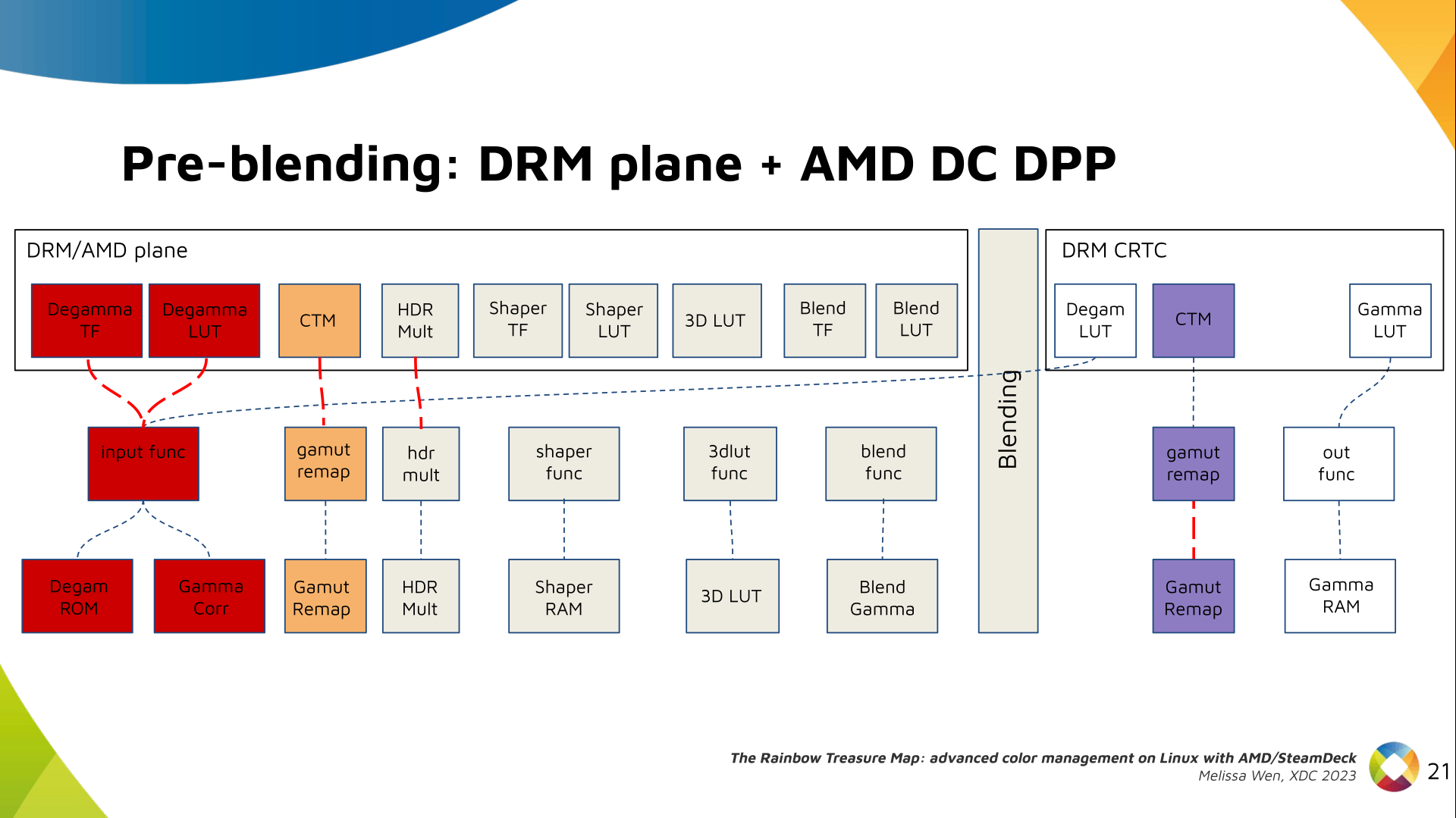 Next, the HDR Multiplier. HDR Multiplier is a factor applied to the color
values of an image to increase their overall brightness.
Next, the HDR Multiplier. HDR Multiplier is a factor applied to the color
values of an image to increase their overall brightness.
 This is useful for converting images from a standard dynamic range (SDR) to a
high dynamic range (HDR). As it can range beyond [0.0, 1.0] subsequent
transforms need to use the PQ(HDR) transfer functions.
This is useful for converting images from a standard dynamic range (SDR) to a
high dynamic range (HDR). As it can range beyond [0.0, 1.0] subsequent
transforms need to use the PQ(HDR) transfer functions.
 And we need a 3D LUT. But 3D LUT has a limited number of entries in each
dimension, so we want to use it in a colorspace that is optimized for human
vision. It means in a non-linear space. To deliver it, userspace may need one
1D LUT before 3D LUT to delinearize content and another one after to linearize
content again for blending.
And we need a 3D LUT. But 3D LUT has a limited number of entries in each
dimension, so we want to use it in a colorspace that is optimized for human
vision. It means in a non-linear space. To deliver it, userspace may need one
1D LUT before 3D LUT to delinearize content and another one after to linearize
content again for blending.
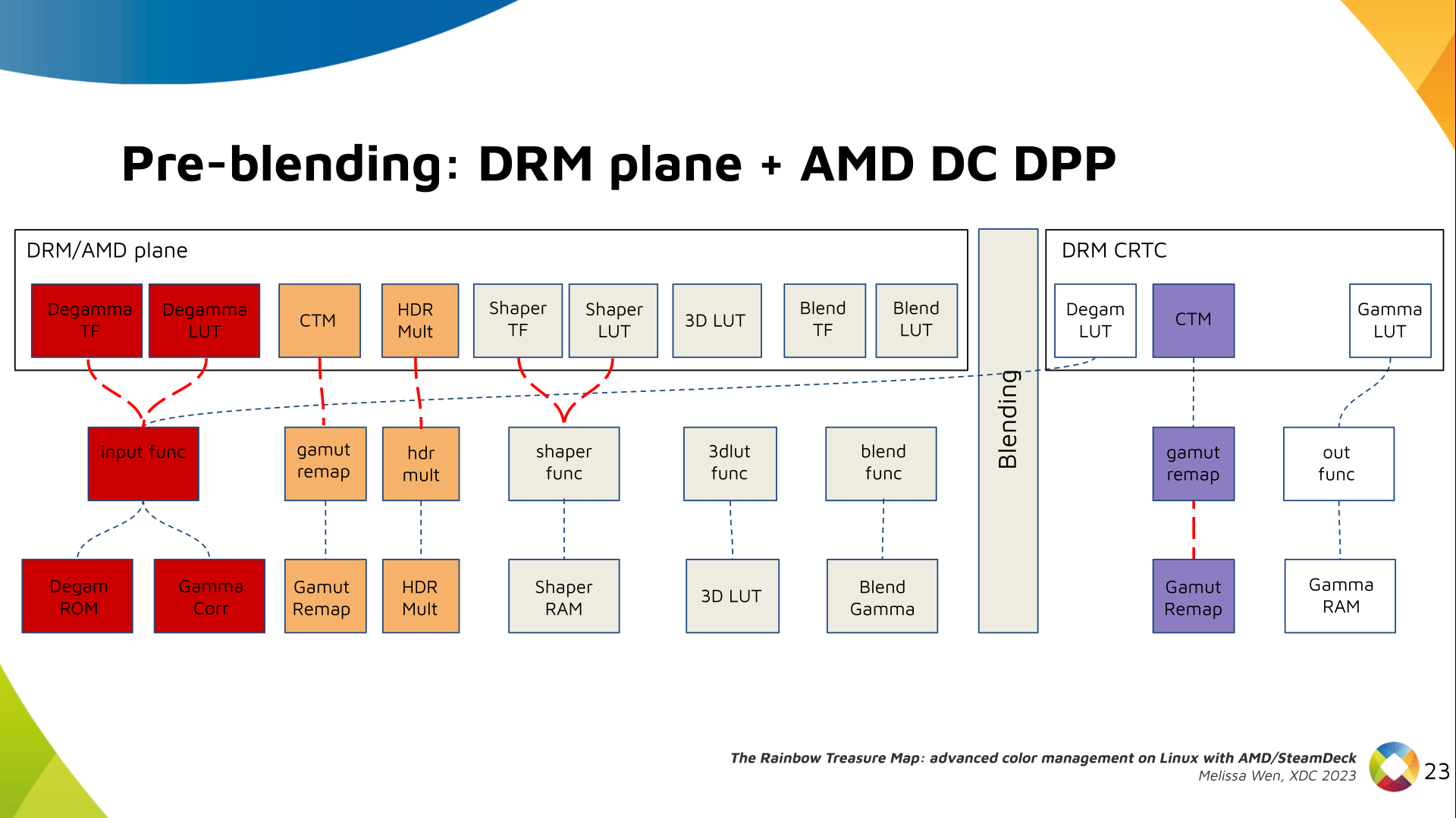
 The pre-3D-LUT curve is called Shaper curve. Unlike Degamma TF, there are no
hardcoded curves for shaper TF, but we can use the AMD color module in the
driver to build the following shaper curves from pre-defined coefficients. The
color module combines the TF and the user LUT values into the LUT that goes to
the DPP Shaper RAM block.
The pre-3D-LUT curve is called Shaper curve. Unlike Degamma TF, there are no
hardcoded curves for shaper TF, but we can use the AMD color module in the
driver to build the following shaper curves from pre-defined coefficients. The
color module combines the TF and the user LUT values into the LUT that goes to
the DPP Shaper RAM block.
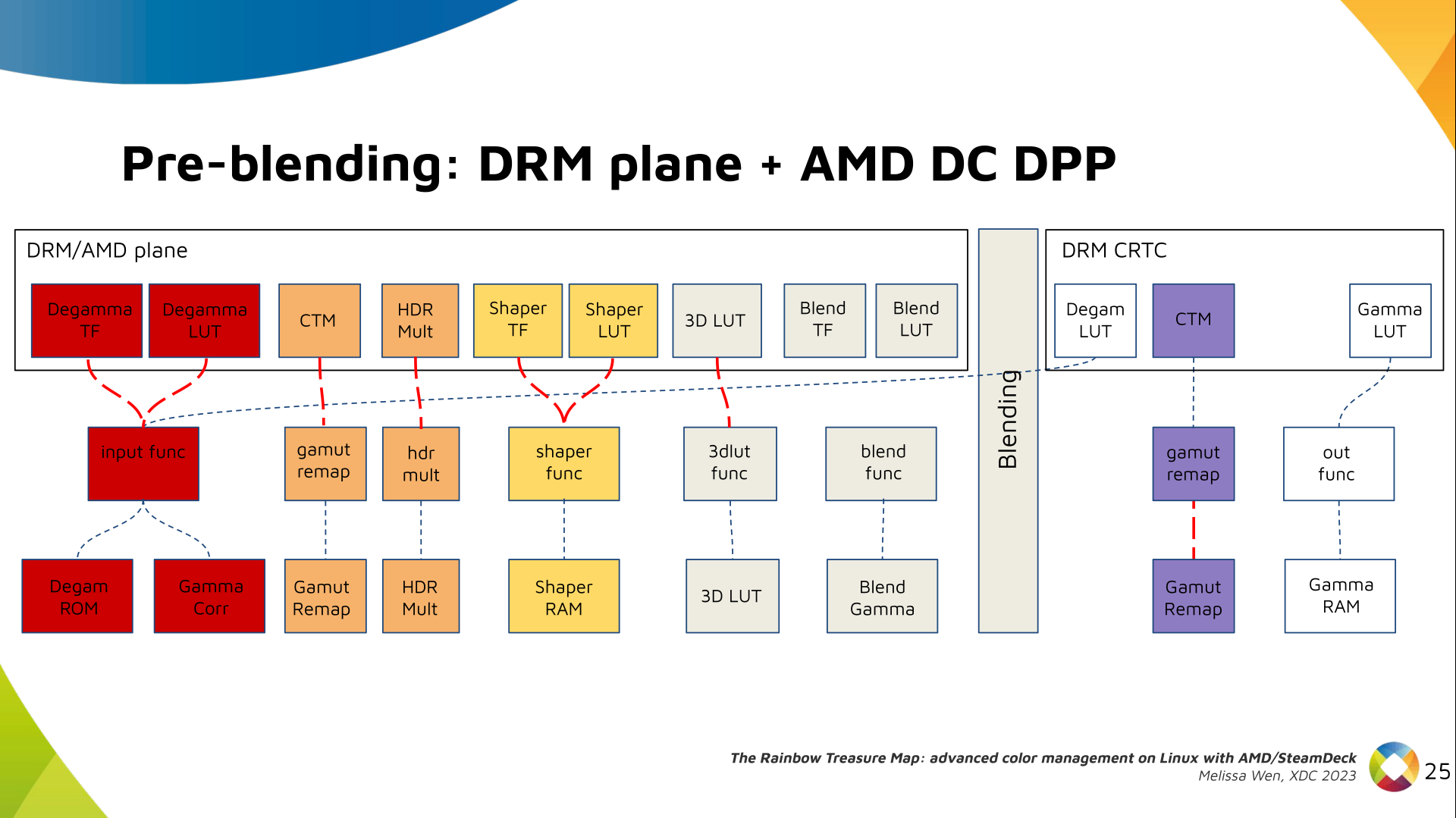 Finally, our rockstar, the 3D LUT. 3D LUT is perfect for complex color
transformations and adjustments between color channels.
Finally, our rockstar, the 3D LUT. 3D LUT is perfect for complex color
transformations and adjustments between color channels.
 3D LUT is also more complex to manage and requires more computational
resources, as a consequence, its number of entries is usually limited. To
overcome this restriction, the array contains samples from the approximated
function and values between samples are estimated by tetrahedral interpolation.
AMD supports 17 and 9 as the size of a single-dimension. Blue is the outermost
dimension, red the innermost.
3D LUT is also more complex to manage and requires more computational
resources, as a consequence, its number of entries is usually limited. To
overcome this restriction, the array contains samples from the approximated
function and values between samples are estimated by tetrahedral interpolation.
AMD supports 17 and 9 as the size of a single-dimension. Blue is the outermost
dimension, red the innermost.
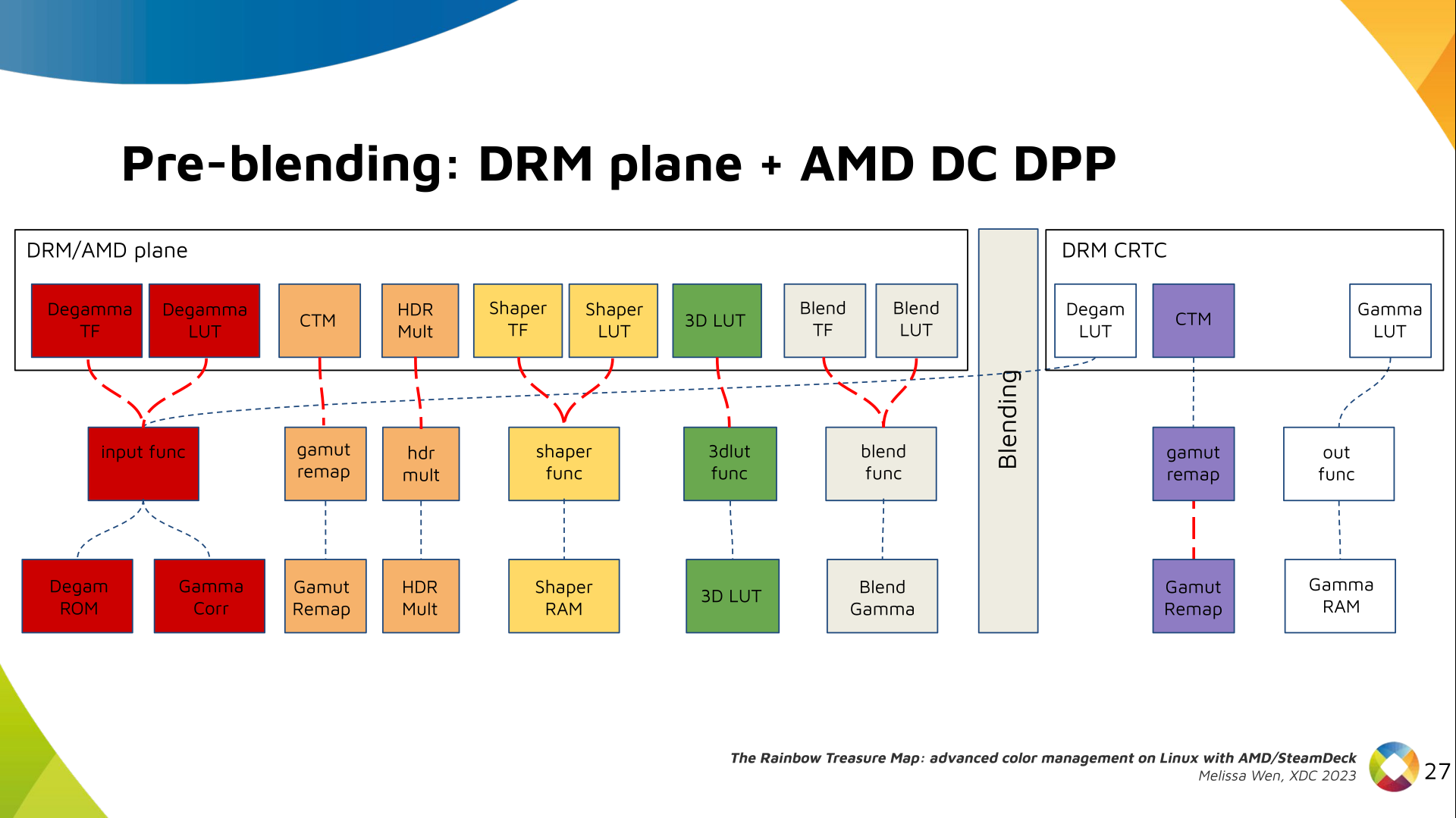 As mentioned, we need a post-3D-LUT curve to linearize the color space before
blending. This is done by Blend TF and LUT.
As mentioned, we need a post-3D-LUT curve to linearize the color space before
blending. This is done by Blend TF and LUT.
 Similar to shaper TF, there are no hardcoded curves for Blend TF. The
pre-defined curves are the same as the Degamma block, but calculated by the
color module. The resulting LUT goes to the DPP Blend RAM block.
Similar to shaper TF, there are no hardcoded curves for Blend TF. The
pre-defined curves are the same as the Degamma block, but calculated by the
color module. The resulting LUT goes to the DPP Blend RAM block.
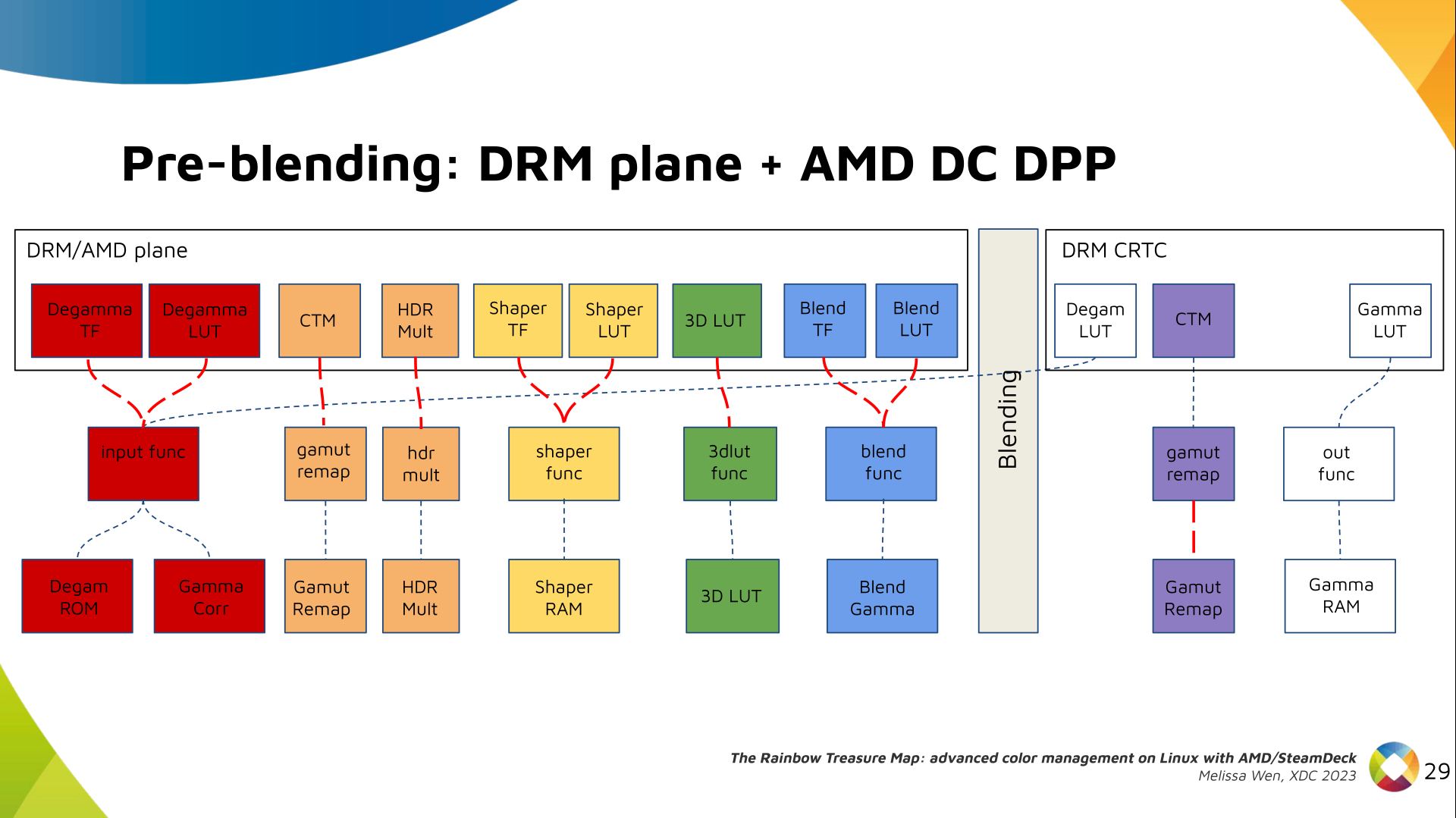 Now we have everything connected before blending. As a conflict between plane
and CRTC Degamma was inevitable, our approach doesn t accept that both are set
at the same time.
Now we have everything connected before blending. As a conflict between plane
and CRTC Degamma was inevitable, our approach doesn t accept that both are set
at the same time.
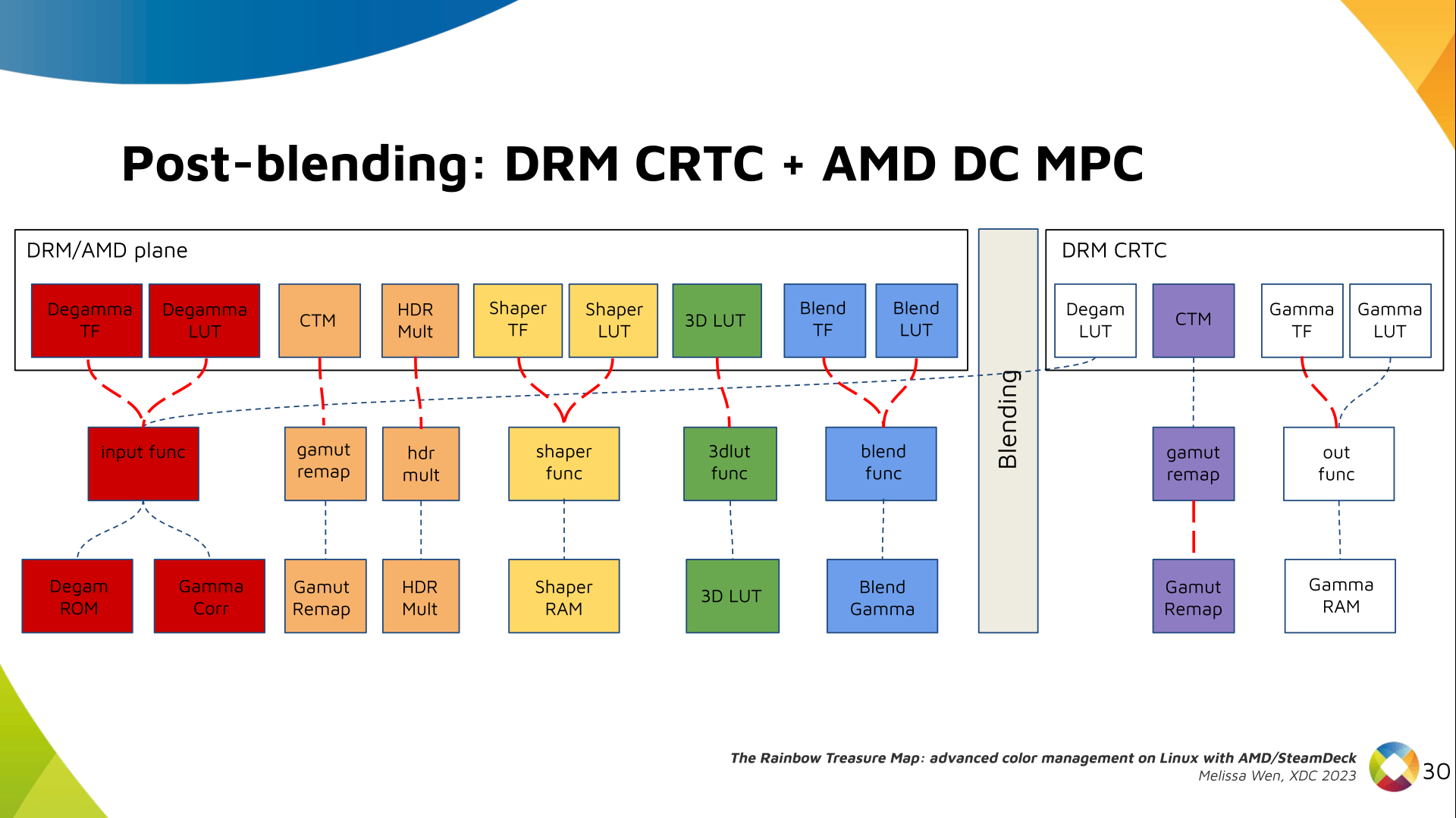 We also optimized the conversion of the framebuffer to wire encoding by adding
support to pre-defined CRTC Gamma TF.
We also optimized the conversion of the framebuffer to wire encoding by adding
support to pre-defined CRTC Gamma TF.
 Again, there are no hardcoded curves and TF and LUT are combined by the AMD
color module. The same types of shaper curves are supported. The resulting LUT
goes to the MPC Gamma RAM block.
Again, there are no hardcoded curves and TF and LUT are combined by the AMD
color module. The same types of shaper curves are supported. The resulting LUT
goes to the MPC Gamma RAM block.
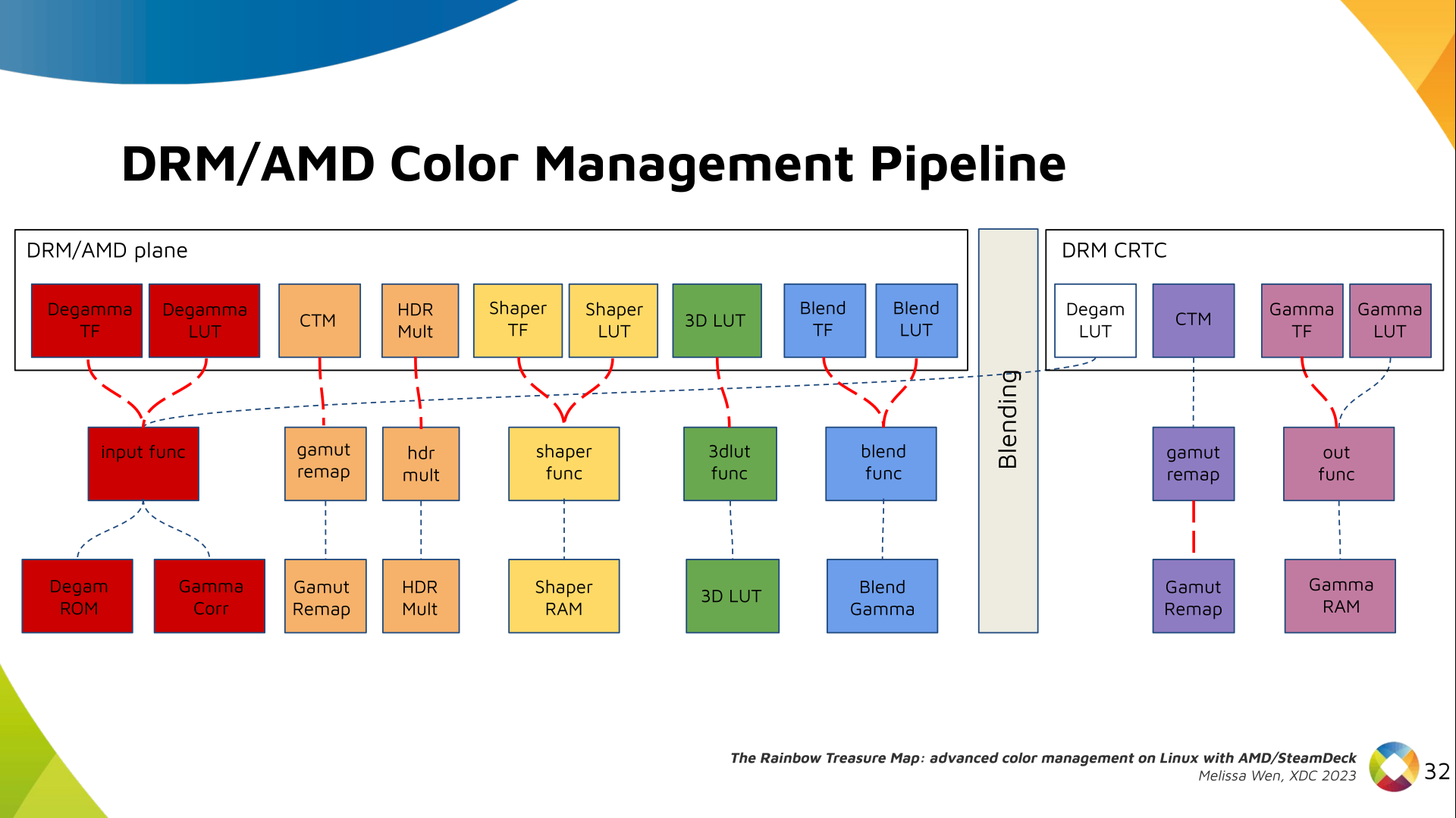 Finally, we arrived in the final version of DRM/AMD driver-specific color
management pipeline. With this knowledge, you re ready to better enjoy the
rainbow treasure of AMD display hardware and the world of graphics computing.
Finally, we arrived in the final version of DRM/AMD driver-specific color
management pipeline. With this knowledge, you re ready to better enjoy the
rainbow treasure of AMD display hardware and the world of graphics computing.
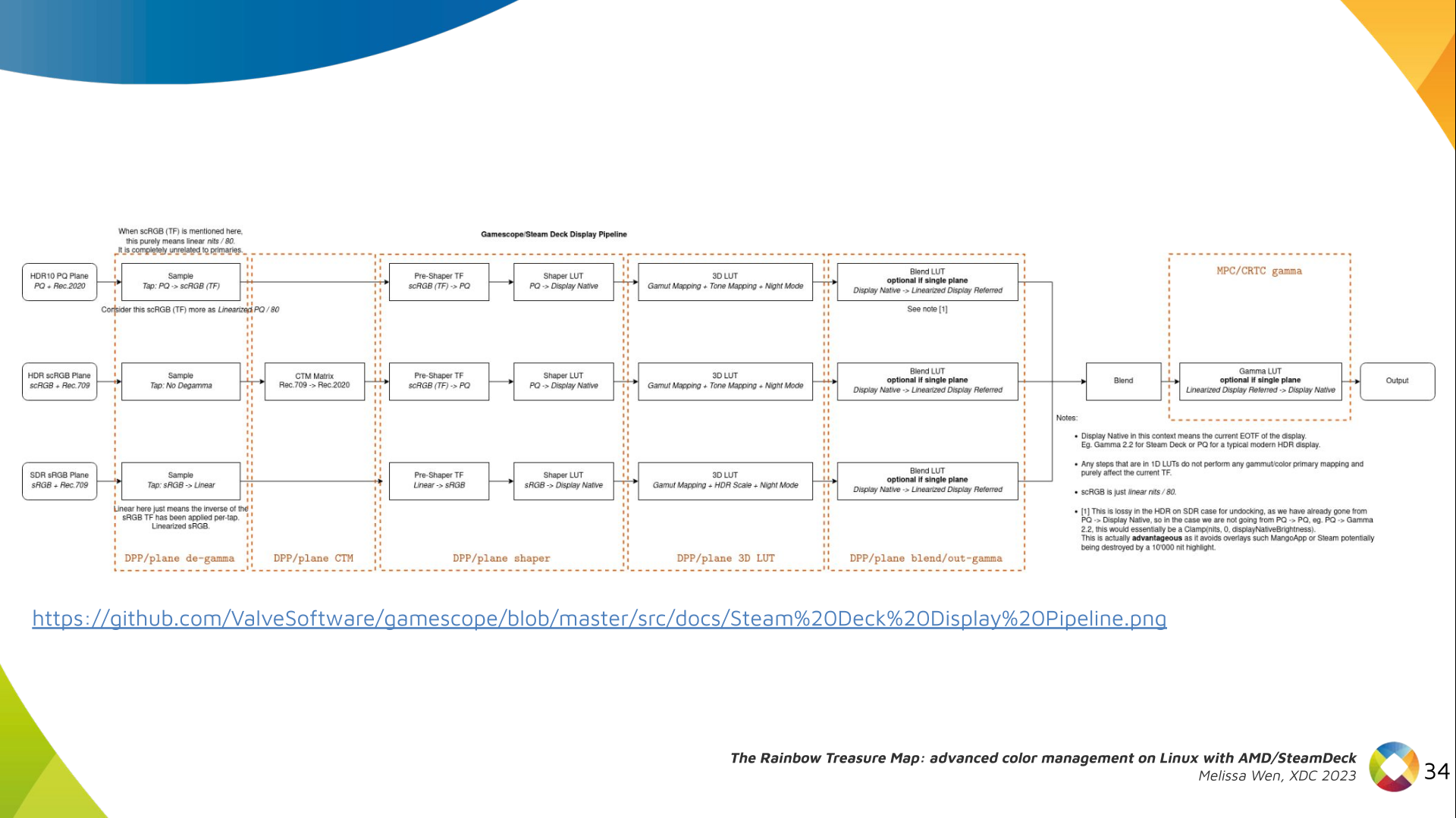 With this work, Gamescope/Steam Deck embraces the color capabilities of the AMD
GPU. We highlight here how we map the Gamescope color pipeline to each AMD
color block.
With this work, Gamescope/Steam Deck embraces the color capabilities of the AMD
GPU. We highlight here how we map the Gamescope color pipeline to each AMD
color block.
 Future works:
The search for the rainbow treasure is not over! The Linux DRM subsystem
contains many hidden treasures from different vendors. We want more complex
color transformations and adjustments available on Linux. We also want to
expose all GPU color capabilities from all hardware vendors to the Linux
userspace.
Thanks Joshua and Harry for this joint work and the Linux DRI community for all feedback and reviews.
The amazing part of this work comes in the next talk with Joshua and The Rainbow Frogs!
Any questions?
Future works:
The search for the rainbow treasure is not over! The Linux DRM subsystem
contains many hidden treasures from different vendors. We want more complex
color transformations and adjustments available on Linux. We also want to
expose all GPU color capabilities from all hardware vendors to the Linux
userspace.
Thanks Joshua and Harry for this joint work and the Linux DRI community for all feedback and reviews.
The amazing part of this work comes in the next talk with Joshua and The Rainbow Frogs!
Any questions?

 Sometimes I have to pore over long debugging logs which have originally been
written out to a terminal and marked up with colour or formatting via ANSI
escape codes. The formatting
definitely makes reading them easier, but I want to read them in Vim, rather
than a terminal, and (out of the box) Vim doesn't render the formatting.
Cue AnsiEsc.vim: an
OG Vim script1 that translates some ANSI escape codes in
particular some colour specifying ones into Vim syntax highlighting.
This makes viewing and navigating around multi-MiB console log files much
nicer.
Sometimes I have to pore over long debugging logs which have originally been
written out to a terminal and marked up with colour or formatting via ANSI
escape codes. The formatting
definitely makes reading them easier, but I want to read them in Vim, rather
than a terminal, and (out of the box) Vim doesn't render the formatting.
Cue AnsiEsc.vim: an
OG Vim script1 that translates some ANSI escape codes in
particular some colour specifying ones into Vim syntax highlighting.
This makes viewing and navigating around multi-MiB console log files much
nicer.
AnsiEsc is old enough to have been distributed as a script, and
then as a "vimball", an invention of the same author to make installing
Vim scripts easier. It pre-dates the current fashion for plugins, but
someone else has updated it and repackaged it as a plugin.
I haven't tried that out. .gitignore file, was bug 774109. It added a script to install the prerequisites to build Firefox on macOS (still called OSX back then), and that would print a message inviting people to obtain a copy of the source code with either Mercurial or Git. That was a precursor to current bootstrap.py, from September 2012.
Following that, as far as I can tell, the first real incursion of Git in the Firefox source tree tooling happened in bug 965120. A few days earlier, bug 952379 had added a mach clang-format command that would apply clang-format-diff to the output from hg diff. Obviously, running hg diff on a Git working tree didn't work, and bug 965120 was filed, and support for Git was added there. That was in January 2014.
A year later, when the initial implementation of mach artifact was added (which ultimately led to artifact builds), Git users were an immediate thought. But while they were considered, it was not to support them, but to avoid actively breaking their workflows. Git support for mach artifact was eventually added 14 months later, in March 2016.
From gecko-dev to git-cinnabar
Let's step back a little here, back to the end of 2014. My user experience with Mercurial had reached a level of dissatisfaction that was enough for me to decide to take that script from a couple years prior and make it work for incremental updates. That meant finding a way to store enough information locally to be able to reconstruct whatever the incremental updates would be relying on (guess why other tools hid a local Mercurial clone under hood). I got something working rather quickly, and after talking to a few people about this side project at the Mozilla Portland All Hands and seeing their excitement, I published a git-remote-hg initial prototype on the last day of the All Hands.
Within weeks, the prototype gained the ability to directly push to Mercurial repositories, and a couple months later, was renamed to git-cinnabar. At that point, as a Git user, instead of cloning the gecko-dev repository from GitHub and switching to a local Mercurial repository whenever you needed to push to a Mercurial repository (i.e. the aforementioned Try server, or, at the time, for reviews), you could just clone and push directly from/to Mercurial, all within Git. And it was fast too. You could get a full clone of mozilla-central in less than half an hour, when at the time, other similar tools would take more than 10 hours (needless to say, it's even worse now).
Another couple months later (we're now at the end of April 2015), git-cinnabar became able to start off a local clone of the gecko-dev repository, rather than clone from scratch, which could be time consuming. But because git-cinnabar and the tool that was updating gecko-dev weren't producing the same commits, this setup was cumbersome and not really recommended. For instance, if you pushed something to mozilla-central with git-cinnabar from a gecko-dev clone, it would come back with a different commit hash in gecko-dev, and you'd have to deal with the divergence.
Eventually, in April 2020, the scripts updating gecko-dev were switched to git-cinnabar, making the use of gecko-dev alongside git-cinnabar a more viable option. Ironically(?), the switch occurred to ease collaboration with KaiOS (you know, the mobile OS born from the ashes of Firefox OS). Well, okay, in all honesty, when the need of syncing in both directions between Git and Mercurial (we only had ever synced from Mercurial to Git) came up, I nudged Mozilla in the direction of git-cinnabar, which, in my (biased but still honest) opinion, was the more reliable option for two-way synchronization (we did have regular conversion problems with hg-git, nothing of the sort has happened since the switch).
One Firefox repository to rule them all
For reasons I don't know, Mozilla decided to use separate Mercurial repositories as "branches". With the switch to the rapid release process in 2011, that meant one repository for nightly (mozilla-central), one for aurora, one for beta, and one for release. And with the addition of Extended Support Releases in 2012, we now add a new ESR repository every year. Boot to Gecko also had its own branches, and so did Fennec (Firefox for Mobile, before Android). There are a lot of them.
And then there are also integration branches, where developer's work lands before being merged in mozilla-central (or backed out if it breaks things), always leaving mozilla-central in a (hopefully) good state. Only one of them remains in use today, though.
I can only suppose that the way Mercurial branches work was not deemed practical. It is worth noting, though, that Mercurial branches are used in some cases, to branch off a dot-release when the next major release process has already started, so it's not a matter of not knowing the feature exists or some such.
In 2016, Gregory Szorc set up a new repository that would contain them all (or at least most of them), which eventually became what is now the mozilla-unified repository. This would e.g. simplify switching between branches when necessary.
7 years later, for some reason, the other "branches" still exist, but most developers are expected to be using mozilla-unified. Mozilla's CI also switched to using mozilla-unified as base repository.
Honestly, I'm not sure why the separate repositories are still the main entry point for pushes, rather than going directly to mozilla-unified, but it probably comes down to switching being work, and not being a top priority. Also, it probably doesn't help that working with multiple heads in Mercurial, even (especially?) with bookmarks, can be a source of confusion. To give an example, if you aren't careful, and do a plain clone of the mozilla-unified repository, you may not end up on the latest mozilla-central changeset, but rather, e.g. one from beta, or some other branch, depending which one was last updated.
Hosting is simple, right?
Put your repository on a server, install hgweb or gitweb, and that's it? Maybe that works for... Mercurial itself, but that repository "only" has slightly over 50k changesets and less than 4k files. Mozilla-central has more than an order of magnitude more changesets (close to 700k) and two orders of magnitude more files (more than 700k if you count the deleted or moved files, 350k if you count the currently existing ones).
And remember, there are a lot of "duplicates" of this repository. And I didn't even mention user repositories and project branches.
Sure, it's a self-inflicted pain, and you'd think it could probably(?) be mitigated with shared repositories. But consider the simple case of two repositories: mozilla-central and autoland. You make autoland use mozilla-central as a shared repository. Now, you push something new to autoland, it's stored in the autoland datastore. Eventually, you merge to mozilla-central. Congratulations, it's now in both datastores, and you'd need to clean-up autoland if you wanted to avoid the duplication.
Now, you'd think mozilla-unified would solve these issues, and it would... to some extent. Because that wouldn't cover user repositories and project branches briefly mentioned above, which in GitHub parlance would be considered as Forks. So you'd want a mega global datastore shared by all repositories, and repositories would need to only expose what they really contain. Does Mercurial support that? I don't think so (okay, I'll give you that: even if it doesn't, it could, but that's extra work). And since we're talking about a transition to Git, does Git support that? You may have read about how you can link to a commit from a fork and make-pretend that it comes from the main repository on GitHub? At least, it shows a warning, now. That's essentially the architectural reason why. So the actual answer is that Git doesn't support it out of the box, but GitHub has some backend magic to handle it somehow (and hopefully, other things like Gitea, Girocco, Gitlab, etc. have something similar).
Now, to come back to the size of the repository. A repository is not a static file. It's a server with which you negotiate what you have against what it has that you want. Then the server bundles what you asked for based on what you said you have. Or in the opposite direction, you negotiate what you have that it doesn't, you send it, and the server incorporates what you sent it. Fortunately the latter is less frequent and requires authentication. But the former is more frequent and CPU intensive. Especially when pulling a large number of changesets, which, incidentally, cloning is.
"But there is a solution for clones" you might say, which is true. That's clonebundles, which offload the CPU intensive part of cloning to a single job scheduled regularly. Guess who implemented it? Mozilla. But that only covers the cloning part. We actually had laid the ground to support offloading large incremental updates and split clones, but that never materialized. Even with all that, that still leaves you with a server that can display file contents, diffs, blames, provide zip archives of a revision, and more, all of which are CPU intensive in their own way.
And these endpoints are regularly abused, and cause extra load to your servers, yes plural, because of course a single server won't handle the load for the number of users of your big repositories. And because your endpoints are abused, you have to close some of them. And I'm not mentioning the Try repository with its tens of thousands of heads, which brings its own sets of problems (and it would have even more heads if we didn't fake-merge them once in a while).
Of course, all the above applies to Git (and it only gained support for something akin to clonebundles last year). So, when the Firefox OS project was stopped, there wasn't much motivation to continue supporting our own Git server, Mercurial still being the official point of entry, and git.mozilla.org was shut down in 2016.
The growing difficulty of maintaining the status quo
Slowly, but steadily in more recent years, as new tooling was added that needed some input from the source code manager, support for Git was more and more consistently added. But at the same time, as people left for other endeavors and weren't necessarily replaced, or more recently with layoffs, resources allocated to such tooling have been spread thin.
Meanwhile, the repository growth didn't take a break, and the Try repository was becoming an increasing pain, with push times quite often exceeding 10 minutes. The ongoing work to move Try pushes to Lando will hide the problem under the rug, but the underlying problem will still exist (although the last version of Mercurial seems to have improved things).
On the flip side, more and more people have been relying on Git for Firefox development, to my own surprise, as I didn't really push for that to happen. It just happened organically, by ways of git-cinnabar existing, providing a compelling experience to those who prefer Git, and, I guess, word of mouth. I was genuinely surprised when I recently heard the use of Git among moz-phab users had surpassed a third. I did, however, occasionally orient people who struggled with Mercurial and said they were more familiar with Git, towards git-cinnabar. I suspect there's a somewhat large number of people who never realized Git was a viable option.
But that, on its own, can come with its own challenges: if you use git-cinnabar without being backed by gecko-dev, you'll have a hard time sharing your branches on GitHub, because you can't push to a fork of gecko-dev without pushing your entire local repository, as they have different commit histories. And switching to gecko-dev when you weren't already using it requires some extra work to rebase all your local branches from the old commit history to the new one.
Clone times with git-cinnabar have also started to go a little out of hand in the past few years, but this was mitigated in a similar manner as with the Mercurial cloning problem: with static files that are refreshed regularly. Ironically, that made cloning with git-cinnabar faster than cloning with Mercurial. But generating those static files is increasingly time-consuming. As of writing, generating those for mozilla-unified takes close to 7 hours. I was predicting clone times over 10 hours "in 5 years" in a post from 4 years ago, I wasn't too far off. With exponential growth, it could still happen, although to be fair, CPUs have improved since. I will explore the performance aspect in a subsequent blog post, alongside the upcoming release of git-cinnabar 0.7.0-b1. I don't even want to check how long it now takes with hg-git or git-remote-hg (they were already taking more than a day when git-cinnabar was taking a couple hours).
I suppose it's about time that I clarify that git-cinnabar has always been a side-project. It hasn't been part of my duties at Mozilla, and the extent to which Mozilla supports git-cinnabar is in the form of taskcluster workers on the community instance for both git-cinnabar CI and generating those clone bundles. Consequently, that makes the above git-cinnabar specific issues a Me problem, rather than a Mozilla problem.
Taking the leap
I can't talk for the people who made the proposal to move to Git, nor for the people who put a green light on it. But I can at least give my perspective.
Developers have regularly asked why Mozilla was still using Mercurial, but I think it was the first time that a formal proposal was laid out. And it came from the Engineering Workflow team, responsible for issue tracking, code reviews, source control, build and more.
It's easy to say "Mozilla should have chosen Git in the first place", but back in 2007, GitHub wasn't there, Bitbucket wasn't there, and all the available options were rather new (especially compared to the then 21 years-old CVS). I think Mozilla made the right choice, all things considered. Had they waited a couple years, the story might have been different.
You might say that Mozilla stayed with Mercurial for so long because of the sunk cost fallacy. I don't think that's true either. But after the biggest Mercurial repository hosting service turned off Mercurial support, and the main contributor to Mercurial going their own way, it's hard to ignore that the landscape has evolved.
And the problems that we regularly encounter with the Mercurial servers are not going to get any better as the repository continues to grow. As far as I know, all the Mercurial repositories bigger than Mozilla's are... not using Mercurial. Google has its own closed-source server, and Facebook has another of its own, and it's not really public either. With resources spread thin, I don't expect Mozilla to be able to continue supporting a Mercurial server indefinitely (although I guess Octobus could be contracted to give a hand, but is that sustainable?).
Mozilla, being a champion of Open Source, also doesn't live in a silo. At some point, you have to meet your contributors where they are. And the Open Source world is now majoritarily using Git. I'm sure the vast majority of new hires at Mozilla in the past, say, 5 years, know Git and have had to learn Mercurial (although they arguably didn't need to). Even within Mozilla, with thousands(!) of repositories on GitHub, Firefox is now actually the exception rather than the norm. I should even actually say Desktop Firefox, because even Mobile Firefox lives on GitHub (although Fenix is moving back in together with Desktop Firefox, and the timing is such that that will probably happen before Firefox moves to Git).
Heck, even Microsoft moved to Git!
With a significant developer base already using Git thanks to git-cinnabar, and all the constraints and problems I mentioned previously, it actually seems natural that a transition (finally) happens. However, had git-cinnabar or something similarly viable not existed, I don't think Mozilla would be in a position to take this decision. On one hand, it probably wouldn't be in the current situation of having to support both Git and Mercurial in the tooling around Firefox, nor the resource constraints related to that. But on the other hand, it would be farther from supporting Git and being able to make the switch in order to address all the other problems.
But... GitHub?
I hope I made a compelling case that hosting is not as simple as it can seem, at the scale of the Firefox repository. It's also not Mozilla's main focus. Mozilla has enough on its plate with the migration of existing infrastructure that does rely on Mercurial to understandably not want to figure out the hosting part, especially with limited resources, and with the mixed experience hosting both Mercurial and git has been so far.
After all, GitHub couldn't even display things like the contributors' graph on gecko-dev until recently, and hosting is literally their job! They still drop the ball on large blames (thankfully we have searchfox for those).
Where does that leave us? Gitlab? For those criticizing GitHub for being proprietary, that's probably not open enough. Cloud Source Repositories? "But GitHub is Microsoft" is a complaint I've read a lot after the announcement. Do you think Google hosting would have appealed to these people? Bitbucket? I'm kind of surprised it wasn't in the list of providers that were considered, but I'm also kind of glad it wasn't (and I'll leave it at that).
I think the only relatively big hosting provider that could have made the people criticizing the choice of GitHub happy is Codeberg, but I hadn't even heard of it before it was mentioned in response to Mozilla's announcement. But really, with literal thousands of Mozilla repositories already on GitHub, with literal tens of millions repositories on the platform overall, the pragmatic in me can't deny that it's an attractive option (and I can't stress enough that I wasn't remotely close to the room where the discussion about what choice to make happened).
"But it's a slippery slope". I can see that being a real concern. LLVM also moved its repository to GitHub (from a (I think) self-hosted Subversion server), and ended up moving off Bugzilla and Phabricator to GitHub issues and PRs four years later. As an occasional contributor to LLVM, I hate this move. I hate the GitHub review UI with a passion.
At least, right now, GitHub PRs are not a viable option for Mozilla, for their lack of support for security related PRs, and the more general shortcomings in the review UI. That doesn't mean things won't change in the future, but let's not get too far ahead of ourselves. The move to Git has just been announced, and the migration has not even begun yet. Just because Mozilla is moving the Firefox repository to GitHub doesn't mean it's locked in forever or that all the eggs are going to be thrown into one basket. If bridges need to be crossed in the future, we'll see then.
So, what's next?
The official announcement said we're not expecting the migration to really begin until six months from now. I'll swim against the current here, and say this: the earlier you can switch to git, the earlier you'll find out what works and what doesn't work for you, whether you already know Git or not.
While there is not one unique workflow, here's what I would recommend anyone who wants to take the leap off Mercurial right now:
git-cinnabar where mach bootstrap would install it.
$ mkdir -p ~/.mozbuild/git-cinnabar
$ cd ~/.mozbuild/git-cinnabar
$ curl -sOL https://raw.githubusercontent.com/glandium/git-cinnabar/master/download.py
$ python3 download.py && rm download.pygit-cinnabar to your PATH. Make sure to also set that wherever you keep your PATH up-to-date (.bashrc or wherever else).
$ PATH=$PATH:$HOME/.mozbuild/git-cinnabar$ git init
$ git remote add origin https://github.com/mozilla/gecko-dev
$ git remote update origin$ git remote set-url origin hg::https://hg.mozilla.org/mozilla-unified
$ git config --local remote.origin.cinnabar-refs bookmarks
$ git remote update origin --prune$ git -c cinnabar.refs=heads fetch hg::$PWD refs/heads/default/*:refs/heads/hg/*hg/<sha1> local branches, not all relevant to you (some come from old branches on mozilla-central). Note that if you're using Mercurial MQ, this will not pull your queues, as they don't exist as heads in the Mercurial repo. You'd need to apply your queues one by one and run the command above for each of them.$ git -c cinnabar.refs=bookmarks fetch hg::$PWD refs/heads/*:refs/heads/hg/*hg/<bookmark_name> branches.
$ git reset $(git cinnabar hg2git $(hg log -r . -T ' node '))mach build won't rebuild anything it doesn't have to.
$ git branch <branch_name> $(git cinnabar hg2git <hg_sha1>).hg directory. Or move it into some empty directory somewhere else, just in case. But don't leave it here, it will only confuse the tooling. Artifact builds WILL be confused, though, and you'll have to ./mach configure before being able to do anything. You may also hit bug 1865299 if your working tree is older than this post.
If you have any problem or question, you can ping me on #git-cinnabar or #git on Matrix. I'll put the instructions above somewhere on wiki.mozilla.org, and we can collaboratively iterate on them.
Now, what the announcement didn't say is that the Git repository WILL NOT be gecko-dev, doesn't exist yet, and WON'T BE COMPATIBLE (trust me, it'll be for the better). Why did I make you do all the above, you ask? Because that won't be a problem. I'll have you covered, I promise. The upcoming release of git-cinnabar 0.7.0-b1 will have a way to smoothly switch between gecko-dev and the future repository (incidentally, that will also allow to switch from a pure git-cinnabar clone to a gecko-dev one, for the git-cinnabar users who have kept reading this far).
What about git-cinnabar?
With Mercurial going the way of the dodo at Mozilla, my own need for git-cinnabar will vanish. Legitimately, this begs the question whether it will still be maintained.
I can't answer for sure. I don't have a crystal ball. However, the needs of the transition itself will motivate me to finish some long-standing things (like finalizing the support for pushing merges, which is currently behind an experimental flag) or implement some missing features (support for creating Mercurial branches).
Git-cinnabar started as a Python script, it grew a sidekick implemented in C, which then incorporated some Rust, which then cannibalized the Python script and took its place. It is now close to 90% Rust, and 10% C (if you don't count the code from Git that is statically linked to it), and has sort of become my Rust playground (it's also, I must admit, a mess, because of its history, but it's getting better). So the day to day use with Mercurial is not my sole motivation to keep developing it. If it were, it would stay stagnant, because all the features I need are there, and the speed is not all that bad, although I know it could be better. Arguably, though, git-cinnabar has been relatively stagnant feature-wise, because all the features I need are there.
So, no, I don't expect git-cinnabar to die along Mercurial use at Mozilla, but I can't really promise anything either.
Final words
That was a long post. But there was a lot of ground to cover. And I still skipped over a bunch of things. I hope I didn't bore you to death. If I did and you're still reading... what's wrong with you? ;)
So this is the end of Mercurial at Mozilla. So long, and thanks for all the fish. But this is also the beginning of a transition that is not easy, and that will not be without hiccups, I'm sure. So fasten your seatbelts (plural), and welcome the change.
To circle back to the clickbait title, did I really kill Mercurial at Mozilla? Of course not. But it's like I stumbled upon a few sparks and tossed a can of gasoline on them. I didn't start the fire, but I sure made it into a proper bonfire... and now it has turned into a wildfire.
And who knows? 15 years from now, someone else might be looking back at how Mozilla picked Git at the wrong time, and that, had we waited a little longer, we would have picked some yet to come new horse. But hey, that's the tech cycle for you.
| Series: | Discworld #34 |
| Publisher: | Harper |
| Copyright: | October 2005 |
| Printing: | November 2014 |
| ISBN: | 0-06-233498-0 |
| Format: | Mass market |
| Pages: | 434 |
/usr/bin/jq -r '."key"' ~/.config/Signal/config.jsonAssuming the result from that command is 'secretkey', which is a hexadecimal number representing the key used to encrypt the database. Next, one can now connect to the database and inject the encryption key for access via SQL to fetch information from the database. Here is an example dumping the database structure:
% sqlcipher ~/.config/Signal/sql/db.sqlite
sqlite> PRAGMA key = "x'secretkey'";
sqlite> .schema
CREATE TABLE sqlite_stat1(tbl,idx,stat);
CREATE TABLE conversations(
id STRING PRIMARY KEY ASC,
json TEXT,
active_at INTEGER,
type STRING,
members TEXT,
name TEXT,
profileName TEXT
, profileFamilyName TEXT, profileFullName TEXT, e164 TEXT, serviceId TEXT, groupId TEXT, profileLastFetchedAt INTEGER);
CREATE TABLE identityKeys(
id STRING PRIMARY KEY ASC,
json TEXT
);
CREATE TABLE items(
id STRING PRIMARY KEY ASC,
json TEXT
);
CREATE TABLE sessions(
id TEXT PRIMARY KEY,
conversationId TEXT,
json TEXT
, ourServiceId STRING, serviceId STRING);
CREATE TABLE attachment_downloads(
id STRING primary key,
timestamp INTEGER,
pending INTEGER,
json TEXT
);
CREATE TABLE sticker_packs(
id TEXT PRIMARY KEY,
key TEXT NOT NULL,
author STRING,
coverStickerId INTEGER,
createdAt INTEGER,
downloadAttempts INTEGER,
installedAt INTEGER,
lastUsed INTEGER,
status STRING,
stickerCount INTEGER,
title STRING
, attemptedStatus STRING, position INTEGER DEFAULT 0 NOT NULL, storageID STRING, storageVersion INTEGER, storageUnknownFields BLOB, storageNeedsSync
INTEGER DEFAULT 0 NOT NULL);
CREATE TABLE stickers(
id INTEGER NOT NULL,
packId TEXT NOT NULL,
emoji STRING,
height INTEGER,
isCoverOnly INTEGER,
lastUsed INTEGER,
path STRING,
width INTEGER,
PRIMARY KEY (id, packId),
CONSTRAINT stickers_fk
FOREIGN KEY (packId)
REFERENCES sticker_packs(id)
ON DELETE CASCADE
);
CREATE TABLE sticker_references(
messageId STRING,
packId TEXT,
CONSTRAINT sticker_references_fk
FOREIGN KEY(packId)
REFERENCES sticker_packs(id)
ON DELETE CASCADE
);
CREATE TABLE emojis(
shortName TEXT PRIMARY KEY,
lastUsage INTEGER
);
CREATE TABLE messages(
rowid INTEGER PRIMARY KEY ASC,
id STRING UNIQUE,
json TEXT,
readStatus INTEGER,
expires_at INTEGER,
sent_at INTEGER,
schemaVersion INTEGER,
conversationId STRING,
received_at INTEGER,
source STRING,
hasAttachments INTEGER,
hasFileAttachments INTEGER,
hasVisualMediaAttachments INTEGER,
expireTimer INTEGER,
expirationStartTimestamp INTEGER,
type STRING,
body TEXT,
messageTimer INTEGER,
messageTimerStart INTEGER,
messageTimerExpiresAt INTEGER,
isErased INTEGER,
isViewOnce INTEGER,
sourceServiceId TEXT, serverGuid STRING NULL, sourceDevice INTEGER, storyId STRING, isStory INTEGER
GENERATED ALWAYS AS (type IS 'story'), isChangeCreatedByUs INTEGER NOT NULL DEFAULT 0, isTimerChangeFromSync INTEGER
GENERATED ALWAYS AS (
json_extract(json, '$.expirationTimerUpdate.fromSync') IS 1
), seenStatus NUMBER default 0, storyDistributionListId STRING, expiresAt INT
GENERATED ALWAYS
AS (ifnull(
expirationStartTimestamp + (expireTimer * 1000),
9007199254740991
)), shouldAffectActivity INTEGER
GENERATED ALWAYS AS (
type IS NULL
OR
type NOT IN (
'change-number-notification',
'contact-removed-notification',
'conversation-merge',
'group-v1-migration',
'keychange',
'message-history-unsynced',
'profile-change',
'story',
'universal-timer-notification',
'verified-change'
)
), shouldAffectPreview INTEGER
GENERATED ALWAYS AS (
type IS NULL
OR
type NOT IN (
'change-number-notification',
'contact-removed-notification',
'conversation-merge',
'group-v1-migration',
'keychange',
'message-history-unsynced',
'profile-change',
'story',
'universal-timer-notification',
'verified-change'
)
), isUserInitiatedMessage INTEGER
GENERATED ALWAYS AS (
type IS NULL
OR
type NOT IN (
'change-number-notification',
'contact-removed-notification',
'conversation-merge',
'group-v1-migration',
'group-v2-change',
'keychange',
'message-history-unsynced',
'profile-change',
'story',
'universal-timer-notification',
'verified-change'
)
), mentionsMe INTEGER NOT NULL DEFAULT 0, isGroupLeaveEvent INTEGER
GENERATED ALWAYS AS (
type IS 'group-v2-change' AND
json_array_length(json_extract(json, '$.groupV2Change.details')) IS 1 AND
json_extract(json, '$.groupV2Change.details[0].type') IS 'member-remove' AND
json_extract(json, '$.groupV2Change.from') IS NOT NULL AND
json_extract(json, '$.groupV2Change.from') IS json_extract(json, '$.groupV2Change.details[0].aci')
), isGroupLeaveEventFromOther INTEGER
GENERATED ALWAYS AS (
isGroupLeaveEvent IS 1
AND
isChangeCreatedByUs IS 0
), callId TEXT
GENERATED ALWAYS AS (
json_extract(json, '$.callId')
));
CREATE TABLE sqlite_stat4(tbl,idx,neq,nlt,ndlt,sample);
CREATE TABLE jobs(
id TEXT PRIMARY KEY,
queueType TEXT STRING NOT NULL,
timestamp INTEGER NOT NULL,
data STRING TEXT
);
CREATE TABLE reactions(
conversationId STRING,
emoji STRING,
fromId STRING,
messageReceivedAt INTEGER,
targetAuthorAci STRING,
targetTimestamp INTEGER,
unread INTEGER
, messageId STRING);
CREATE TABLE senderKeys(
id TEXT PRIMARY KEY NOT NULL,
senderId TEXT NOT NULL,
distributionId TEXT NOT NULL,
data BLOB NOT NULL,
lastUpdatedDate NUMBER NOT NULL
);
CREATE TABLE unprocessed(
id STRING PRIMARY KEY ASC,
timestamp INTEGER,
version INTEGER,
attempts INTEGER,
envelope TEXT,
decrypted TEXT,
source TEXT,
serverTimestamp INTEGER,
sourceServiceId STRING
, serverGuid STRING NULL, sourceDevice INTEGER, receivedAtCounter INTEGER, urgent INTEGER, story INTEGER);
CREATE TABLE sendLogPayloads(
id INTEGER PRIMARY KEY ASC,
timestamp INTEGER NOT NULL,
contentHint INTEGER NOT NULL,
proto BLOB NOT NULL
, urgent INTEGER, hasPniSignatureMessage INTEGER DEFAULT 0 NOT NULL);
CREATE TABLE sendLogRecipients(
payloadId INTEGER NOT NULL,
recipientServiceId STRING NOT NULL,
deviceId INTEGER NOT NULL,
PRIMARY KEY (payloadId, recipientServiceId, deviceId),
CONSTRAINT sendLogRecipientsForeignKey
FOREIGN KEY (payloadId)
REFERENCES sendLogPayloads(id)
ON DELETE CASCADE
);
CREATE TABLE sendLogMessageIds(
payloadId INTEGER NOT NULL,
messageId STRING NOT NULL,
PRIMARY KEY (payloadId, messageId),
CONSTRAINT sendLogMessageIdsForeignKey
FOREIGN KEY (payloadId)
REFERENCES sendLogPayloads(id)
ON DELETE CASCADE
);
CREATE TABLE preKeys(
id STRING PRIMARY KEY ASC,
json TEXT
, ourServiceId NUMBER
GENERATED ALWAYS AS (json_extract(json, '$.ourServiceId')));
CREATE TABLE signedPreKeys(
id STRING PRIMARY KEY ASC,
json TEXT
, ourServiceId NUMBER
GENERATED ALWAYS AS (json_extract(json, '$.ourServiceId')));
CREATE TABLE badges(
id TEXT PRIMARY KEY,
category TEXT NOT NULL,
name TEXT NOT NULL,
descriptionTemplate TEXT NOT NULL
);
CREATE TABLE badgeImageFiles(
badgeId TEXT REFERENCES badges(id)
ON DELETE CASCADE
ON UPDATE CASCADE,
'order' INTEGER NOT NULL,
url TEXT NOT NULL,
localPath TEXT,
theme TEXT NOT NULL
);
CREATE TABLE storyReads (
authorId STRING NOT NULL,
conversationId STRING NOT NULL,
storyId STRING NOT NULL,
storyReadDate NUMBER NOT NULL,
PRIMARY KEY (authorId, storyId)
);
CREATE TABLE storyDistributions(
id STRING PRIMARY KEY NOT NULL,
name TEXT,
senderKeyInfoJson STRING
, deletedAtTimestamp INTEGER, allowsReplies INTEGER, isBlockList INTEGER, storageID STRING, storageVersion INTEGER, storageUnknownFields BLOB, storageNeedsSync INTEGER);
CREATE TABLE storyDistributionMembers(
listId STRING NOT NULL REFERENCES storyDistributions(id)
ON DELETE CASCADE
ON UPDATE CASCADE,
serviceId STRING NOT NULL,
PRIMARY KEY (listId, serviceId)
);
CREATE TABLE uninstalled_sticker_packs (
id STRING NOT NULL PRIMARY KEY,
uninstalledAt NUMBER NOT NULL,
storageID STRING,
storageVersion NUMBER,
storageUnknownFields BLOB,
storageNeedsSync INTEGER NOT NULL
);
CREATE TABLE groupCallRingCancellations(
ringId INTEGER PRIMARY KEY,
createdAt INTEGER NOT NULL
);
CREATE TABLE IF NOT EXISTS 'messages_fts_data'(id INTEGER PRIMARY KEY, block BLOB);
CREATE TABLE IF NOT EXISTS 'messages_fts_idx'(segid, term, pgno, PRIMARY KEY(segid, term)) WITHOUT ROWID;
CREATE TABLE IF NOT EXISTS 'messages_fts_content'(id INTEGER PRIMARY KEY, c0);
CREATE TABLE IF NOT EXISTS 'messages_fts_docsize'(id INTEGER PRIMARY KEY, sz BLOB);
CREATE TABLE IF NOT EXISTS 'messages_fts_config'(k PRIMARY KEY, v) WITHOUT ROWID;
CREATE TABLE edited_messages(
messageId STRING REFERENCES messages(id)
ON DELETE CASCADE,
sentAt INTEGER,
readStatus INTEGER
, conversationId STRING);
CREATE TABLE mentions (
messageId REFERENCES messages(id) ON DELETE CASCADE,
mentionAci STRING,
start INTEGER,
length INTEGER
);
CREATE TABLE kyberPreKeys(
id STRING PRIMARY KEY NOT NULL,
json TEXT NOT NULL, ourServiceId NUMBER
GENERATED ALWAYS AS (json_extract(json, '$.ourServiceId')));
CREATE TABLE callsHistory (
callId TEXT PRIMARY KEY,
peerId TEXT NOT NULL, -- conversation id (legacy) uuid groupId roomId
ringerId TEXT DEFAULT NULL, -- ringer uuid
mode TEXT NOT NULL, -- enum "Direct" "Group"
type TEXT NOT NULL, -- enum "Audio" "Video" "Group"
direction TEXT NOT NULL, -- enum "Incoming" "Outgoing
-- Direct: enum "Pending" "Missed" "Accepted" "Deleted"
-- Group: enum "GenericGroupCall" "OutgoingRing" "Ringing" "Joined" "Missed" "Declined" "Accepted" "Deleted"
status TEXT NOT NULL,
timestamp INTEGER NOT NULL,
UNIQUE (callId, peerId) ON CONFLICT FAIL
);
[ dropped all indexes to save space in this blog post ]
CREATE TRIGGER messages_on_view_once_update AFTER UPDATE ON messages
WHEN
new.body IS NOT NULL AND new.isViewOnce = 1
BEGIN
DELETE FROM messages_fts WHERE rowid = old.rowid;
END;
CREATE TRIGGER messages_on_insert AFTER INSERT ON messages
WHEN new.isViewOnce IS NOT 1 AND new.storyId IS NULL
BEGIN
INSERT INTO messages_fts
(rowid, body)
VALUES
(new.rowid, new.body);
END;
CREATE TRIGGER messages_on_delete AFTER DELETE ON messages BEGIN
DELETE FROM messages_fts WHERE rowid = old.rowid;
DELETE FROM sendLogPayloads WHERE id IN (
SELECT payloadId FROM sendLogMessageIds
WHERE messageId = old.id
);
DELETE FROM reactions WHERE rowid IN (
SELECT rowid FROM reactions
WHERE messageId = old.id
);
DELETE FROM storyReads WHERE storyId = old.storyId;
END;
CREATE VIRTUAL TABLE messages_fts USING fts5(
body,
tokenize = 'signal_tokenizer'
);
CREATE TRIGGER messages_on_update AFTER UPDATE ON messages
WHEN
(new.body IS NULL OR old.body IS NOT new.body) AND
new.isViewOnce IS NOT 1 AND new.storyId IS NULL
BEGIN
DELETE FROM messages_fts WHERE rowid = old.rowid;
INSERT INTO messages_fts
(rowid, body)
VALUES
(new.rowid, new.body);
END;
CREATE TRIGGER messages_on_insert_insert_mentions AFTER INSERT ON messages
BEGIN
INSERT INTO mentions (messageId, mentionAci, start, length)
SELECT messages.id, bodyRanges.value ->> 'mentionAci' as mentionAci,
bodyRanges.value ->> 'start' as start,
bodyRanges.value ->> 'length' as length
FROM messages, json_each(messages.json ->> 'bodyRanges') as bodyRanges
WHERE bodyRanges.value ->> 'mentionAci' IS NOT NULL
AND messages.id = new.id;
END;
CREATE TRIGGER messages_on_update_update_mentions AFTER UPDATE ON messages
BEGIN
DELETE FROM mentions WHERE messageId = new.id;
INSERT INTO mentions (messageId, mentionAci, start, length)
SELECT messages.id, bodyRanges.value ->> 'mentionAci' as mentionAci,
bodyRanges.value ->> 'start' as start,
bodyRanges.value ->> 'length' as length
FROM messages, json_each(messages.json ->> 'bodyRanges') as bodyRanges
WHERE bodyRanges.value ->> 'mentionAci' IS NOT NULL
AND messages.id = new.id;
END;
sqlite>
Finally I have the tool needed to inspect and process Signal
messages that I need, without using the vendor provided client. Now
on to transforming it to a more useful format.
As usual, if you use Bitcoin and want to show your support of my
activities, please send Bitcoin donations to my address
15oWEoG9dUPovwmUL9KWAnYRtNJEkP1u1b.
gitsigns is a Neovim plugin
which adds a wonderfully subtle colour annotation in the left-hand gutter to
reflect changes in the buffer since the last git commit1.
My long-term habit with Vim and Git is to frequently background Vim (^Z) to invoke
the git command directly and then foreground Vim again (fg). Over the last few
years I've been trying more and more to call vim-fugitive from
within Vim instead. (I still do rebases and most merges the old-fashioned way).
For the most part Gitsigns is a nice passive addition to that, but it can also
do a lot of useful things that Fugitive also does. Previewing changed hunks in a
little floating window, in particular when resolving an awkward merge conflict, is
very handy.
 The DRM/KMS framework provides the atomic API for color management through KMS
properties represented by
The DRM/KMS framework provides the atomic API for color management through KMS
properties represented by struct drm_property. We extended the color
management interface exposed to userspace by leveraging existing resources and
connecting them with driver-specific functions for managing modeset properties.
On the AMD DC layer, the interface with hardware color blocks is established.
The AMD DC layer contains OS-agnostic components that are shared across
different platforms, making it an invaluable resource. This layer already
implements hardware programming and resource management, simplifying the external
developer s task. While examining the DC code, we gain insights into the color
pipeline and capabilities, even without direct access to specifications.
Additionally, AMD developers provide essential support by answering queries and
reviewing our work upstream.
The primary challenge involved identifying and understanding relevant AMD DC
code to configure each color block in the color pipeline. However, the ultimate
goal was to bridge the DC color capabilities with the DRM API. For this, we
changed the AMD DM, the OS-dependent layer connecting the
DC interface to the DRM/KMS framework. We defined and managed driver-specific
color properties, facilitated the transport of user space data to the DC, and
translated DRM features and settings to the DC interface. Considerations were
also made for differences in the color pipeline based on hardware capabilities.
AMD s display driver supports the following pre-defined transfer functions (aka named fixed curves):
- OETF: the opto-electronic transfer function, which converts linear scene light into the video signal, typically within a camera.
- EOTF: electro-optical transfer function, which converts the video signal into the linear light output of the display.
- OOTF: opto-optical transfer function, which has the role of applying the rendering intent .
These capabilities vary depending on the hardware block, with some utilizing hardcoded curves and others relying on AMD s color module to construct curves from standardized coefficients. It also supports user/custom curves built from a lookup table.
- Linear/Unity: linear/identity relationship between pixel value and luminance value;
- Gamma 2.2, Gamma 2.4, Gamma 2.6: pure power functions;
- sRGB: 2.4: The piece-wise transfer function from IEC 61966-2-1:1999;
- BT.709: has a linear segment in the bottom part and then a power function with a 0.45 (~1/2.22) gamma for the rest of the range; standardized by ITU-R BT.709-6;
- PQ (Perceptual Quantizer): used for HDR display, allows luminance range capability of 0 to 10,000 nits; standardized by SMPTE ST 2084.
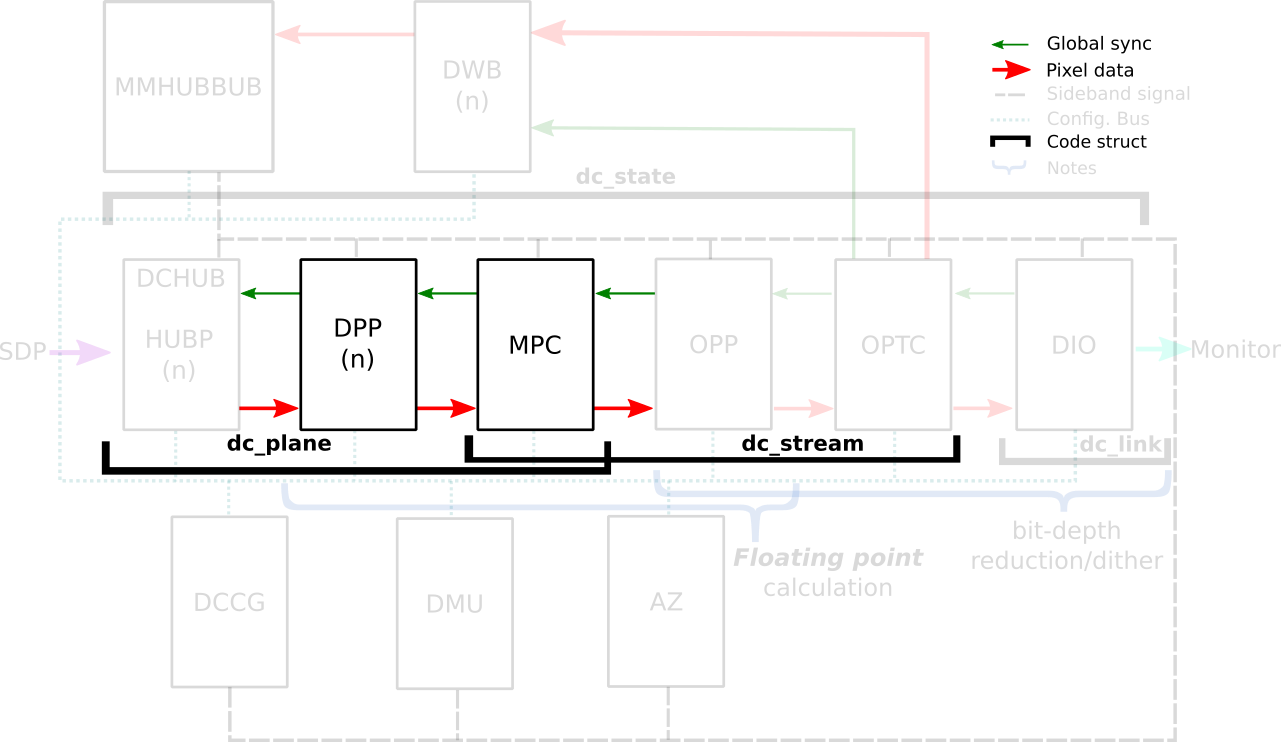 In the AMD Display Core Next hardware pipeline, we encounter two hardware
blocks with color capabilities: the Display Pipe and Plane (DPP) and the
Multiple Pipe/Plane Combined (MPC). The DPP handles color adjustments per plane
before blending, while the MPC engages in post-blending color adjustments.
In short, we expect DPP color capabilities to match up with DRM plane
properties, and MPC color capabilities to play nice with DRM CRTC properties.
Note: here s the catch there are some DRM CRTC color transformations that
don t have a corresponding AMD MPC color block, and vice versa. It s like a
puzzle, and we re here to solve it!
In the AMD Display Core Next hardware pipeline, we encounter two hardware
blocks with color capabilities: the Display Pipe and Plane (DPP) and the
Multiple Pipe/Plane Combined (MPC). The DPP handles color adjustments per plane
before blending, while the MPC engages in post-blending color adjustments.
In short, we expect DPP color capabilities to match up with DRM plane
properties, and MPC color capabilities to play nice with DRM CRTC properties.
Note: here s the catch there are some DRM CRTC color transformations that
don t have a corresponding AMD MPC color block, and vice versa. It s like a
puzzle, and we re here to solve it!
struct
dpp_color_caps
and struct
mpc_color_caps.
The AMD Steam Deck hardware provides a tangible example of these capabilities.
Therefore, we take SteamDeck/DCN301 driver as an example and look at the Color
pipeline capabilities described in the file:
driver/gpu/drm/amd/display/dcn301/dcn301_resources.c
/* Color pipeline capabilities */
dc->caps.color.dpp.dcn_arch = 1; // If it is a Display Core Next (DCN): yes. Zero means DCE.
dc->caps.color.dpp.input_lut_shared = 0;
dc->caps.color.dpp.icsc = 1; // Intput Color Space Conversion (CSC) matrix.
dc->caps.color.dpp.dgam_ram = 0; // The old degamma block for degamma curve (hardcoded and LUT). Gamma correction is the new one.
dc->caps.color.dpp.dgam_rom_caps.srgb = 1; // sRGB hardcoded curve support
dc->caps.color.dpp.dgam_rom_caps.bt2020 = 1; // BT2020 hardcoded curve support (seems not actually in use)
dc->caps.color.dpp.dgam_rom_caps.gamma2_2 = 1; // Gamma 2.2 hardcoded curve support
dc->caps.color.dpp.dgam_rom_caps.pq = 1; // PQ hardcoded curve support
dc->caps.color.dpp.dgam_rom_caps.hlg = 1; // HLG hardcoded curve support
dc->caps.color.dpp.post_csc = 1; // CSC matrix
dc->caps.color.dpp.gamma_corr = 1; // New Gamma Correction block for degamma user LUT;
dc->caps.color.dpp.dgam_rom_for_yuv = 0;
dc->caps.color.dpp.hw_3d_lut = 1; // 3D LUT support. If so, it's always preceded by a shaper curve.
dc->caps.color.dpp.ogam_ram = 1; // Blend Gamma block for custom curve just after blending
// no OGAM ROM on DCN301
dc->caps.color.dpp.ogam_rom_caps.srgb = 0;
dc->caps.color.dpp.ogam_rom_caps.bt2020 = 0;
dc->caps.color.dpp.ogam_rom_caps.gamma2_2 = 0;
dc->caps.color.dpp.ogam_rom_caps.pq = 0;
dc->caps.color.dpp.ogam_rom_caps.hlg = 0;
dc->caps.color.dpp.ocsc = 0;
dc->caps.color.mpc.gamut_remap = 1; // Post-blending CTM (pre-blending CTM is always supported)
dc->caps.color.mpc.num_3dluts = pool->base.res_cap->num_mpc_3dlut; // Post-blending 3D LUT (preceded by shaper curve)
dc->caps.color.mpc.ogam_ram = 1; // Post-blending regamma.
// No pre-defined TF supported for regamma.
dc->caps.color.mpc.ogam_rom_caps.srgb = 0;
dc->caps.color.mpc.ogam_rom_caps.bt2020 = 0;
dc->caps.color.mpc.ogam_rom_caps.gamma2_2 = 0;
dc->caps.color.mpc.ogam_rom_caps.pq = 0;
dc->caps.color.mpc.ogam_rom_caps.hlg = 0;
dc->caps.color.mpc.ocsc = 1; // Output CSC matrix.
struct dpp_color_caps,
struct mpc_color_caps
and struct rom_curve_caps.
Now, using this guideline, we go through color capabilities of DPP and MPC blocks and talk more
about mapping driver-specific properties to corresponding color blocks.
dc->caps.color.dpp.dcn_arch
dc->caps.color.dpp.dgam_ram, dc->caps.color.dpp.dgam_rom_caps,dc->caps.color.dpp.gamma_corr
AMD Plane Degamma data is mapped to the initial stage of the DPP pipeline. It
is utilized to transition from scanout/encoded values to linear values for
arithmetic operations. Plane Degamma supports both pre-defined transfer
functions and 1D LUTs, depending on the hardware generation. DCN2 and older
families handle both types of curve in the Degamma RAM block
(dc->caps.color.dpp.dgam_ram); DCN3+ separate hardcoded curves and 1D LUT
into two block: Degamma ROM (dc->caps.color.dpp.dgam_rom_caps) and Gamma
correction block (dc->caps.color.dpp.gamma_corr), respectively.
Pre-defined transfer functions:
struct drm_color_lut elements. Setting TF = Identity/Default and LUT as
NULL means bypass.
References:
struct drm_color_ctm_3x4. Setting NULL means bypass.
References:
dc->caps.color.dpp.hw_3d_lut
The Shaper block fine-tunes color adjustments before applying the 3D LUT,
optimizing the use of the limited entries in each dimension of the 3D LUT. On
AMD hardware, a 3D LUT always means a preceding shaper 1D LUT used for
delinearizing and/or normalizing the color space before applying a 3D LUT, so
this entry on DPP color caps dc->caps.color.dpp.hw_3d_lut means support for
both shaper 1D LUT and 3D LUT.
Pre-defined transfer function enables delinearizing content with or without
shaper LUT, where AMD color module calculates the resulted shaper curve. Shaper
curves go from linear values to encoded values. If we are already in a
non-linear space and/or don t need to normalize values, we can set a Identity TF
for shaper that works similar to bypass and is also the default TF value.
Pre-defined transfer functions:
calculate_curve() function in the file
amd/display/modules/color/color_gamma.c.struct drm_color_lut elements. When setting Plane Shaper TF (!= Identity)
and LUT at the same time, the color module will combine the pre-defined TF and
the custom LUT values into the LUT that s actually programmed. Setting TF =
Identity/Default and LUT as NULL works as bypass.
References:
dc->caps.color.dpp.hw_3d_lut
The 3D LUT in the DPP block facilitates complex color transformations and
adjustments. 3D LUT is a three-dimensional array where each element is an RGB
triplet. As mentioned before, the dc->caps.color.dpp.hw_3d_lut describe if
DPP 3D LUT is supported.
The AMD driver-specific property advertise the size of a single dimension via
LUT3D_SIZE property. Plane 3D LUT is a blog property where the data is interpreted
as an array of struct drm_color_lut elements and the number of entries is
LUT3D_SIZE cubic. The array contains samples from the approximated function.
Values between samples are estimated by tetrahedral interpolation
The array is accessed with three indices, one for each input dimension (color
channel), blue being the outermost dimension, red the innermost. This
distribution is better visualized when examining the code in
[RFC PATCH 5/5] drm/amd/display: Fill 3D LUT from userspace by Alex Hung:
+ for (nib = 0; nib < 17; nib++)
+ for (nig = 0; nig < 17; nig++)
+ for (nir = 0; nir < 17; nir++)
+ ind_lut = 3 * (nib + 17*nig + 289*nir);
+
+ rgb_area[ind].red = rgb_lib[ind_lut + 0];
+ rgb_area[ind].green = rgb_lib[ind_lut + 1];
+ rgb_area[ind].blue = rgb_lib[ind_lut + 2];
+ ind++;
+
+
+
+ /* Stride and bit depth are not programmable by API yet.
+ * Therefore, only supports 17x17x17 3D LUT (12-bit).
+ */
+ lut->lut_3d.use_tetrahedral_9 = false;
+ lut->lut_3d.use_12bits = true;
+ lut->state.bits.initialized = 1;
+ __drm_3dlut_to_dc_3dlut(drm_lut, drm_lut3d_size, &lut->lut_3d,
+ lut->lut_3d.use_tetrahedral_9,
+ MAX_COLOR_3DLUT_BITDEPTH);
dc->caps.color.dpp.ogam_ram
The Blend/Out Gamma block applies the final touch-up before blending, allowing
users to linearize content after 3D LUT and just before the blending. It supports both 1D LUT
and pre-defined TF. We can see Shaper and Blend LUTs as 1D LUTs that are
sandwich the 3D LUT. So, if we don t need 3D LUT transformations, we may want
to only use Degamma block to linearize and skip Shaper, 3D LUT and Blend.
Pre-defined transfer function:
struct drm_color_lut elements. If plane_blend_tf_property != Identity TF,
AMD color module will combine the user LUT values with pre-defined TF into the
LUT parameters to be programmed. Setting TF = Identity/Default and LUT to NULL
means bypass.
References:
struct drm_color_lut elements. Setting NULL means bypass.
Not really supported. The driver is currently reusing the DPP degamma LUT block
(dc->caps.color.dpp.dgam_ram and dc->caps.color.dpp.gamma_corr) for
supporting DRM CRTC Degamma LUT, as explaning by [PATCH v3 20/32]
drm/amd/display: reject atomic commit if setting both plane and CRTC
degamma.
dc->caps.color.mpc.gamut_remap
It sets the current transformation matrix (CTM) apply to pixel data after the
lookup through the degamma LUT and before the lookup through the gamma LUT. The
data is interpreted as a struct drm_color_ctm. Setting NULL means bypass.
dc->caps.color.mpc.ogam_ram
After all that, you might still want to convert the content to wire encoding.
No worries, in addition to DRM CRTC 1D LUT, we ve got a AMD CRTC gamma transfer
function (TF) to make it happen. Possible TF values are defined by enum
amdgpu_transfer_function.
Pre-defined transfer functions:
struct drm_color_lut elements. When setting CRTC Gamma TF (!= Identity)
and LUT at the same time, the color module will combine the pre-defined TF and
the custom LUT values into the LUT that s actually programmed. Setting TF =
Identity/Default and LUT to NULL means bypass.
References:
color_range and color_encoding properties. It is used for color space
conversion of the input content. On the other hand, we have de DC Output CSC
(OCSC) sets pre-defined coefficients from DRM connector colorspace
properties. It is uses for color space conversion of the composed image to the
one supported by the sink.
References:
sudo vpnc-connect
and later on sudo vpnc-disconnect. In the past that also
managed to restore my resolv.conf, currently it doesn't.
According to a colleague that's also the case for Ubuntu.
Taking a step back, the sane way would be to use the
NetworkManager vpnc plugin, but that does not work with
this specific case because we use uncool VPN tech which
requires the Enable weak authentication setting for vpnc.
There is a feature request open for that one at
https://gitlab.gnome.org/GNOME/NetworkManager-vpnc/-/issues/11
Taking another step back I thought that it shouldn't be that
hard to add some checkbox, a boolean and render out another
config flag or line in a config file. Not as intuitive as I
thought this mix of XML and C. So let's quickly look elsewhere.
What happens is that the backup files in /var/run/vpnc/ are
created by the vpnc-scripts script called vpnc-script, but not
moved back, because it adds some pid as a suffix and the pid is
not the final pid of the vpnc process. Basically it can not find
the backup when it tries to restore it. So I decided to replace the
pid guessing code with a suffix made up of the gateway IP and the
tun interface name. No idea if that is stable in all circumstance
(someone with a vpn name DNS RR?) or several connections to different
gateways. But good enough for myself, so here is my patch:
vpnc-scripts [master]$ cat debian/patches/replace-pid-detection
Index: vpnc-scripts/vpnc-script
===================================================================
--- vpnc-scripts.orig/vpnc-script
+++ vpnc-scripts/vpnc-script
@@ -91,21 +91,15 @@ OS=" uname -s "
HOOKS_DIR=/etc/vpnc
-# Use the PID of the controlling process (vpnc or OpenConnect) to
-# uniquely identify this VPN connection. Normally, the parent process
-# is a shell, and the grandparent's PID is the relevant one.
-# OpenConnect v9.0+ provides VPNPID, so we don't need to determine it.
-if [ -z "$VPNPID" ]; then
- VPNPID=$PPID
- PCMD= ps -c -o cmd= -p $PPID
- case "$PCMD" in
- *sh) VPNPID= ps -o ppid= -p $PPID ;;
- esac
+# This whole script is called twice via vpnc-connect. On the first run
+# the variables are empty. Catch that and move on when they're there.
+if [ -n "$VPNGATEWAY" ]; then
+ BACKUPID="$ VPNGATEWAY _$ TUNDEV "
+ DEFAULT_ROUTE_FILE=/var/run/vpnc/defaultroute.$ BACKUPID
+ DEFAULT_ROUTE_FILE_IPV6=/var/run/vpnc/defaultroute_ipv6.$ BACKUPID
+ RESOLV_CONF_BACKUP=/var/run/vpnc/resolv.conf-backup.$ BACKUPID
fi
-DEFAULT_ROUTE_FILE=/var/run/vpnc/defaultroute.$ VPNPID
-DEFAULT_ROUTE_FILE_IPV6=/var/run/vpnc/defaultroute_ipv6.$ VPNPID
-RESOLV_CONF_BACKUP=/var/run/vpnc/resolv.conf-backup.$ VPNPID
SCRIPTNAME= basename $0
# some systems, eg. Darwin & FreeBSD, prune /var/run on boot
--enable-weak-authentication. The beauty is,
all of this will break on updates, so at some point someone has to
understand GTK4 to fix the NetworkManager plugin for good. 
 Dormitory room in Zostel Ernakulam, Kochi.
Dormitory room in Zostel Ernakulam, Kochi.
 Beds in Zostel Ernakulam, Kochi.
Beds in Zostel Ernakulam, Kochi.
 Onam sadya menu from Brindhavan restaurant.
Onam sadya menu from Brindhavan restaurant.
 Sadya lined up for serving
Sadya lined up for serving
 Sadya thali served on banana leaf.
Sadya thali served on banana leaf.
 We were treated with such views during the Wayanad trip.
We were treated with such views during the Wayanad trip.
 A road in Rippon.
A road in Rippon.
 Entry to Kanthanpara Falls.
Entry to Kanthanpara Falls.
 Kanthanpara Falls.
Kanthanpara Falls.
 A view of Zostel Wayanad.
A view of Zostel Wayanad.
 A map of Wayanad showing tourist places.
A map of Wayanad showing tourist places.
 A view from inside the Zostel Wayanad property.
A view from inside the Zostel Wayanad property.
 Terrain during trekking towards the Chembra peak.
Terrain during trekking towards the Chembra peak.
 Heart-shaped lake at the Chembra peak.
Heart-shaped lake at the Chembra peak.
 Me at the heart-shaped lake.
Me at the heart-shaped lake.
 Views from the top of the Chembra peak.
Views from the top of the Chembra peak.
 View of another peak from the heart-shaped lake.
View of another peak from the heart-shaped lake.
2 files changed, 23 insertions(+), 8 deletions(-),
this page is the first one to have any keywords. And the funny thing,
after initially struggling to write a single line of Haskell, the
final version of the keywords is something like this:
And I wrote that as is, compiled successfully, and did the right thing
from the first try. I only write some Haskell code 2-3 times per
year, but man, I love this language.
Until next time, hopefully before 2024
| Series: | Discworld #31 |
| Publisher: | Harper |
| Copyright: | October 2003 |
| Printing: | August 2014 |
| ISBN: | 0-06-230741-X |
| Format: | Mass market |
| Pages: | 457 |
There was always a war. Usually they were border disputes, the national equivalent of complaining that the neighbor was letting their hedge row grow too long. Sometimes they were bigger. Borogravia was a peace-loving country in the middle of treacherous, devious, warlike enemies. They had to be treacherous, devious, and warlike; otherwise, we wouldn't be fighting them, eh? There was always a war.Polly's brother, who wanted nothing more than to paint (something that the god Nuggan and the ever-present Duchess certainly did not consider appropriate for a strapping young man), was recruited to fight in the war and never came back. Polly is worried about him and tired of waiting for news. Exit Polly, innkeeper's daughter, and enter the young lad Oliver Perks, who finds the army recruiters in a tavern the next town over. One kiss of the Duchess's portrait later, and Polly is a private in the Borogravian army. I suspect this is some people's favorite Discworld novel. If so, I understand why. It was not mine, for reasons that I'll get into, but which are largely not Pratchett's fault and fall more into the category of pet peeves. Pratchett has dealt with both war and gender in the same book before. Jingo is also about a war pushed by a ruling class for stupid reasons, and featured a substantial subplot about Nobby cross-dressing that turns into a deeper character re-evaluation. I thought the war part of Monstrous Regiment was weaker (this is part of my complaint below), but gender gets a considerably deeper treatment. Monstrous Regiment is partly about how arbitrary and nonsensical gender roles are, and largely about how arbitrary and abusive social structures can become weirdly enduring because they build up their own internally reinforcing momentum. No one knows how to stop them, and a lot of people find familiar misery less frightening than unknown change, so the structure continues despite serving no defensible purpose. Recently, there was a brief attempt in some circles to claim Pratchett posthumously for the anti-transgender cause in the UK. Pratchett's daughter was having none of it, and any Pratchett reader should have been able to reject that out of hand, but Monstrous Regiment is a comprehensive refutation written by Pratchett himself some twenty years earlier. Polly is herself is not transgender. She thinks of herself as a woman throughout the book; she's just pretending to be a boy. But she also rejects binary gender roles with the scathing dismissal of someone who knows first-hand how superficial they are, and there is at least one transgender character in this novel (although to say who would be a spoiler). By the end of the book, you will have no doubt that Pratchett's opinion about people imposing gender roles on others is the same as his opinion about every other attempt to treat people as things. That said, by 2023 standards the treatment of gender here seems... naive? I think 2003 may sadly have been a more innocent time. We're now deep into a vicious backlash against any attempt to question binary gender assignment, but very little of that nastiness and malice is present here. In one way, this is a feature; there's more than enough of that in real life. However, it also makes the undermining of gender roles feel a bit too easy. There are good in-story reasons for why it's relatively simple for Polly to pass as a boy, but I still spent a lot of the book thinking that passing as a private in the army would be a lot harder and riskier than this. Pratchett can't resist a lot of cross-dressing and gender befuddlement jokes, all of which are kindly and wry but (at least for me) hit a bit differently in 2023 than they would have in 2003. The climax of the story is also a reference to a classic UK novel that to even name would be to spoil one or both of the books, but which I thought pulled the punch of the story and dissipated a lot of the built-up emotional energy. My larger complaints, though, are more idiosyncratic. This is a war novel about the enlisted ranks, including the hazing rituals involved in joining the military. There are things I love about military fiction, but apparently that reaction requires I have some sympathy for the fight or the goals of the institution. Monstrous Regiment falls into the class of war stories where the war is pointless and the system is abusive but the camaraderie in the ranks makes service oddly worthwhile, if not entirely justifiable. This is a real feeling that many veterans do have about military service, and I don't mean to question it, but apparently reading about it makes me grumbly. There's only so much of the apparently gruff sergeant with a heart of gold that I can take before I start wondering why we glorify hazing rituals as a type of tough love, or why the person with some authority doesn't put a direct stop to nastiness instead of providing moral support so subtle you could easily blink and miss it. Let alone the more basic problems like none of these people should have to be here doing this, or lots of people are being mangled and killed to make possible this heart-warming friendship. Like I said earlier, this is a me problem, not a Pratchett problem. He's writing a perfectly reasonable story in a genre I just happen to dislike. He's even undermining the genre in the process, just not quite fast enough or thoroughly enough for my taste. A related grumble is that Monstrous Regiment is very invested in the military trope of naive and somewhat incompetent officers who have to be led by the nose by experienced sergeants into making the right decision. I have never been in the military, but I work in an industry in which it is common to treat management as useless incompetents at best and actively malicious forces at worst. This is, to me, one of the most persistently obnoxious attitudes in my profession, and apparently my dislike of it carries over as a low tolerance for this very common attitude towards military hierarchy. A full expansion of this point would mostly be about the purpose of management, division of labor, and people's persistent dismissal of skills they don't personally have and may perceive as gendered, and while some of that is tangentially related to this book, it's not closely-related enough for me to bore you with it in a review. Maybe I'll write a stand-alone blog post someday. Suffice it to say that Pratchett deployed a common trope that most people would laugh at and read past without a second thought, but that for my own reasons started getting under my skin by the end of the novel. All of that grumbling aside, I did like this book. It is a very solid Discworld novel that does all the typical things a Discworld novel does: likable protagonists you can root for, odd and fascinating side characters, sharp and witty observations of human nature, and a mostly enjoyable ending where most of the right things happen. Polly is great; I was very happy to read a book from her perspective and would happily read more. Vimes makes a few appearances being Vimes, and while I found his approach in this book less satisfying than in Jingo, I'll still take it. And the examination of gender roles, even if a bit less fraught than current politics, is solid Pratchett morality. The best part of this book for me, by far, is Wazzer. I think that subplot was the most Discworld part of this book: a deeply devout belief in a pseudo-godlike figure that is part of the abusive social structure that creates many of the problems of the book becomes something considerably stranger and more wonderful. There is a type of belief that is so powerful that it transforms the target of that belief, at least in worlds like Discworld that have a lot of ambient magic. Not many people have that type of belief, and having it is not a comfortable experience, but it makes for a truly excellent story. Monstrous Regiment is a solid Discworld novel. It was not one of my favorites, but it probably will be someone else's favorite for a host of good reasons. Good stuff; if you've read this far, you will enjoy it. Followed by A Hat Full of Sky in publication order, and thematically (but very loosely) by Going Postal. Rating: 8 out of 10
DKIM-Signature header then the message is DKIM signed. If they don t, then it wasn t. Most email traversing the public internet is DKIM signed nowadays; so if they don t see the header probably they re not looking using the right tools, or they re actually on the same email system as you.
In messages signed by a system running dkim-rotate, there will also be a header about the key rotation, to notify potential verifiers of the situation. Other systems that avoid non-repudiation-through-DKIM might do something similar. dkim-rotate s header looks like this:
DKIM-Signature-Warning: NOTE REGARDING DKIM KEY COMPROMISE
https://www.chiark.greenend.org.uk/dkim-rotate/README.txt
https://www.chiark.greenend.org.uk/dkim-rotate/ae/aeb689c2066c5b3fee673355309fe1c7.pem # save the message as test-email.mbox
apt install libmail-dkim-perl # or equivalent on another distro
dkimproxy-verify <test-email.mbox originator address: ijackson@chiark.greenend.org.uk
signature identity: @chiark.greenend.org.uk
verify result: pass
...verify result: fail (body has been altered) then probably your friend didn t manage to faithfully save the unalterered raw message.
Checking old emails cannot be verified
When you both have that working, have your friend find an older email of yours, from (say) month ago. Perform the same steps.
Hopefully they will see something like this:
originator address: ijackson@chiark.greenend.org.uk
signature identity: @chiark.greenend.org.uk
verify result: fail (bad RSA signature) verify result: invalid (public key: not available)verify result: pass, then they have verified that that old email of yours is genuine. Anyone who had a copy of the mail can do that. This is good for email thieves, but not for you.
For email admins: announcing dkim-rotate 1.0
I have been running dkim-rotate 0.4 on my infrastructure, since last August. and I had entirely forgotten about it: it has run flawlessly for a year. I was reminded of the topic by seeing DKIM in other blog posts. Obviously, it is time to decreee that dkim-rotate is 1.0.
If you re a mail system administrator, your users are best served if you use something like dkim-rotate. The package is available in Debian stable, and supports Exim out of the box, but other MTAs should be easy to support too, via some simple ad-hoc scripting.
Limitation of this approach
Even with this key rotation approach, emails remain nonrepudiable for a short period after they re sent - typically, a few days.
Someone who obtains a leaked email very promptly, and shows it to the journalist (for example) right away, can still convince the journalist. This is not great, but at least it doesn t apply to the vast bulk of your email archive.
There are possible email protocol improvements which might help, but they re quite out of scope for this article.
Edited 2023-10-01 00:20 +01:00 to fix some grammarNext.
{kind=link}